Example of fitting with a GP: K2-229
In this notebook, we will fit the two-planet system K2-229 both without and with a Gaussian Process (GP), to demonstrate how GPs can be essential for modelling correlated noise from stellar activity.
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import ravest.prior
from ravest.fit import Fitter
from ravest.model import calculate_mpsini
from ravest.param import Parameter, Parameterisation
The data for K2-229 was used in Osborne et al 2025 A&A, 693, A4 (2025) and downloaded from VizieR J/A+A/693/A4.
fpath = Path.cwd() / "example_data" / "K2-229.csv"
data = pd.read_csv(fpath)
data
| BJD | RV | e_RV | FWHM | BIS | System | TIC | GaiaDR2 | tel | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.457798e+06 | 22965.967262 | 1.580978 | 0.002236 | 0.002236 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 1 | 2.457798e+06 | 22971.043308 | 1.471306 | 0.002081 | 0.002081 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 2 | 2.457797e+06 | 22963.492334 | 1.562922 | 0.002210 | 0.002210 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 3 | 2.457797e+06 | 22967.865369 | 1.499985 | 0.002121 | 0.002121 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 4 | 2.457796e+06 | 22970.042232 | 1.363895 | 0.001929 | 0.001929 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 115 | 2.457803e+06 | 22992.061104 | 1.902412 | 0.002690 | 0.002690 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 116 | 2.457803e+06 | 22986.700197 | 1.512577 | 0.002139 | 0.002139 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 117 | 2.457803e+06 | 22988.074353 | 1.580983 | 0.002236 | 0.002236 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 118 | 2.457802e+06 | 22988.311991 | 1.448587 | 0.002049 | 0.002049 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
| 119 | 2.457802e+06 | 22982.833389 | 1.475159 | 0.002086 | 0.002086 | K2-229 | 98720809 | 3583630929786305280 | HARPS |
120 rows × 9 columns
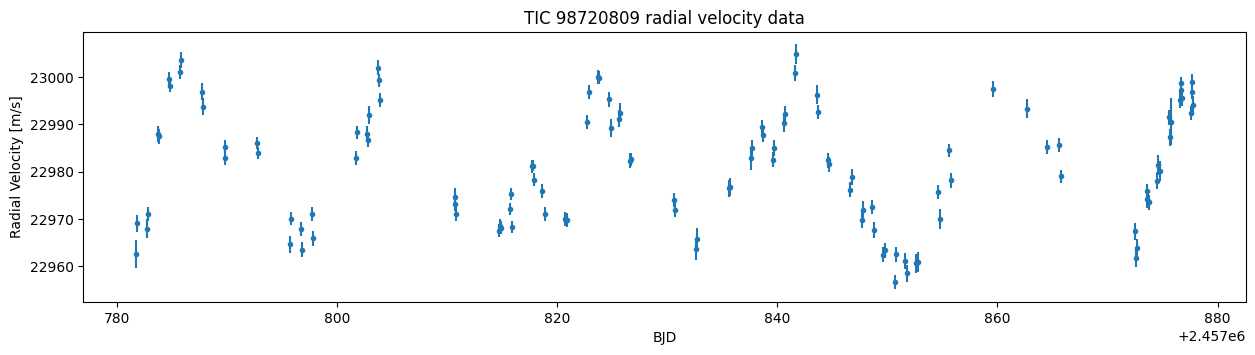
plt.figure(figsize=(15,3.5))
plt.title("TIC 98720809 radial velocity data")
plt.ylabel("Radial Velocity [m/s]")
plt.xlabel("BJD")
plt.errorbar(data["BJD"], data["RV"], yerr=data["e_RV"], marker=".", linestyle="None")
plt.show()
Fitting without GP (white-noise model)
For more details on fitting a white noise model, see the fitting tutorial notebook.
Note that we truncate the BJD times to BTJD (Barycentric TESS Julian Date) by subtracting 2457000 (this is done mostly to make plot labels and \(T_c\) values more readable!)
parameterisation=Parameterisation("P K e w Tc")
fitter = Fitter(planet_letters=["b","c"], parameterisation=parameterisation)
fitter.add_data(
time=(data["BJD"].to_numpy()-2457000),
vel=data["RV"].to_numpy(),
velerr=data["e_RV"].to_numpy(),
instrument=data["tel"].to_numpy(),
t0=np.mean(data["BJD"].to_numpy()-2457000),
)
fitter
<ravest.fit.Fitter at 0x10a8f4190>
Construct the parameters dict. The values for \(P\) and \(T_c\) are the reported values from Supplementary Table 6 of Santerne et al. 2018. For the sake of making this notebook run quickly, we use their reported values as starting points.
# Construct the params dict
params = {
"P_b": Parameter(0.584249, "d", fixed=False),
"K_b": Parameter(10, "m/s", fixed=False),
"e_b": Parameter(0, "", fixed=True),
"w_b": Parameter(np.pi/2, "", fixed=True),
"Tc_b": Parameter(2457586.9750-2457000, "d", fixed=False),
"P_c": Parameter(8.32835, "d", fixed=False),
"K_c": Parameter(10, "m/s", fixed=False),
"e_c": Parameter(0, "", fixed=True),
"w_c": Parameter(np.pi/2, "", fixed=True),
"Tc_c": Parameter(2457536.3647-2457000, "d", fixed=False),
"g_HARPS": Parameter(np.mean(data["RV"].to_numpy()), "m/s", fixed=False),
"gd": Parameter(0, "m/s/day", fixed=True),
"gdd": Parameter(0, "m/s/day^2", fixed=True),
"jit_HARPS": Parameter(0.01, "m/s", fixed=False),
}
fitter.params = params
fitter.params
{'P_b': Parameter(value=0.584249, unit='d', fixed=False),
'K_b': Parameter(value=10, unit='m/s', fixed=False),
'e_b': Parameter(value=0, unit='', fixed=True),
'w_b': Parameter(value=1.5707963267948966, unit='', fixed=True),
'Tc_b': Parameter(value=586.9750000000931, unit='d', fixed=False),
'P_c': Parameter(value=8.32835, unit='d', fixed=False),
'K_c': Parameter(value=10, unit='m/s', fixed=False),
'e_c': Parameter(value=0, unit='', fixed=True),
'w_c': Parameter(value=1.5707963267948966, unit='', fixed=True),
'Tc_c': Parameter(value=536.3646999998018, unit='d', fixed=False),
'g_HARPS': Parameter(value=np.float64(22981.045158814868), unit='m/s', fixed=False),
'gd': Parameter(value=0, unit='m/s/day', fixed=True),
'gdd': Parameter(value=0, unit='m/s/day^2', fixed=True),
'jit_HARPS': Parameter(value=0.01, unit='m/s', fixed=False)}
Define the prior functions for the free parameters. You can see a list of available prior functions at ravest.prior.PRIOR_FUNCTIONS.
ravest.prior.PRIOR_FUNCTIONS
['Uniform',
'EccentricityUniform',
'Normal',
'TruncatedNormal',
'HalfNormal',
'Rayleigh',
'VanEylen19Mixture',
'Beta']
These are again based on the values used in Santerne et al. 2018.
rv_range = np.max(data["RV"]) - np.min(data["RV"])
# Construct the priors dict. Every parameter that isn't fixed requires a prior.
priors = {
"P_b": ravest.prior.Normal(0.584250, 0.000015),
"K_b": ravest.prior.Uniform(0,100),
"Tc_b": ravest.prior.Normal(586.9746, 0.001),
"P_c": ravest.prior.Normal(8.3274, 0.01),
"K_c": ravest.prior.Uniform(0,100),
"Tc_c": ravest.prior.Normal(536.3766, 0.001),
"g_HARPS": ravest.prior.Uniform(params["g_HARPS"].value-rv_range, params["g_HARPS"].value+rv_range),
"jit_HARPS": ravest.prior.Uniform(0, 100),
}
fitter.priors = priors
fitter.priors
{'P_b': Normal(mean=0.58425, std=1.5e-05),
'K_b': Uniform(lower=0, upper=100),
'Tc_b': Normal(mean=586.9746, std=0.001),
'P_c': Normal(mean=8.3274, std=0.01),
'K_c': Uniform(lower=0, upper=100),
'Tc_c': Normal(mean=536.3766, std=0.001),
'g_HARPS': Uniform(lower=22932.870701387474, upper=23029.219616242262),
'jit_HARPS': Uniform(lower=0, upper=100)}
map_results = fitter.find_map_estimate(method="Powell")
map_results
MAP parameter results: {'P_b': np.float64(0.5842500280693586), 'K_b': np.float64(1.1866800881872943), 'Tc_b': np.float64(586.9746000576196), 'P_c': np.float64(8.340952412834282), 'K_c': np.float64(4.402464797444496), 'Tc_c': np.float64(536.3766040234813), 'g_HARPS': np.float64(22980.853469668127), 'jit_HARPS': np.float64(11.750801790738771)}
message: Optimization terminated successfully.
success: True
status: 0
fun: 460.67140313317435
x: [ 5.843e-01 1.187e+00 5.870e+02 8.341e+00 4.402e+00
5.364e+02 2.298e+04 1.175e+01]
nit: 3
direc: [[ 1.000e+00 0.000e+00 ... 0.000e+00 0.000e+00]
[ 0.000e+00 1.000e+00 ... 0.000e+00 0.000e+00]
...
[ 0.000e+00 0.000e+00 ... 1.000e+00 0.000e+00]
[ 4.293e-07 1.562e-02 ... -2.540e-02 6.455e-03]]
nfev: 231
fitter.plot_MAP_rv(map_result=map_results)
fitter.plot_MAP_phase(planet_letter="b", map_result=map_results)
fitter.plot_MAP_phase(planet_letter="c", map_result=map_results)
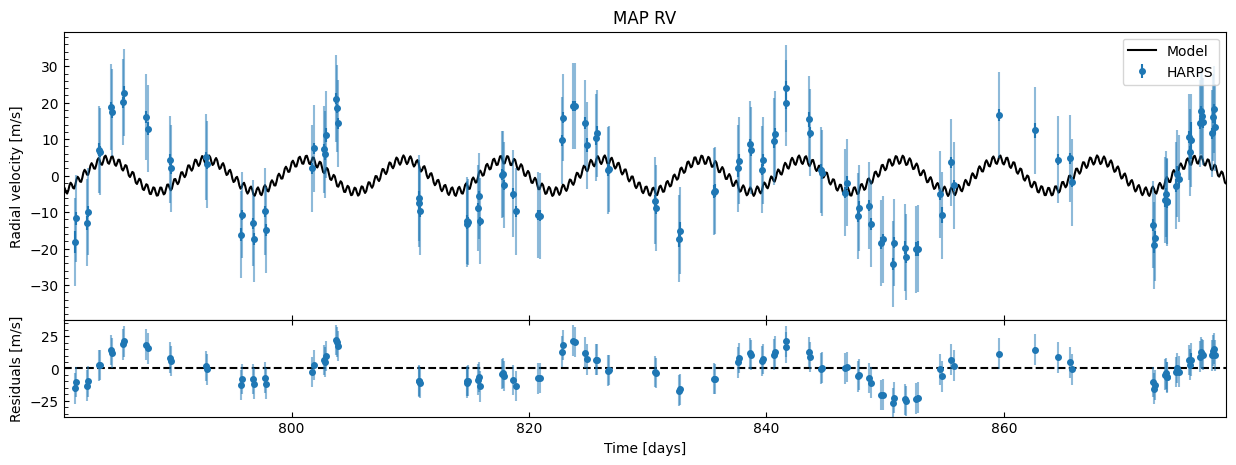
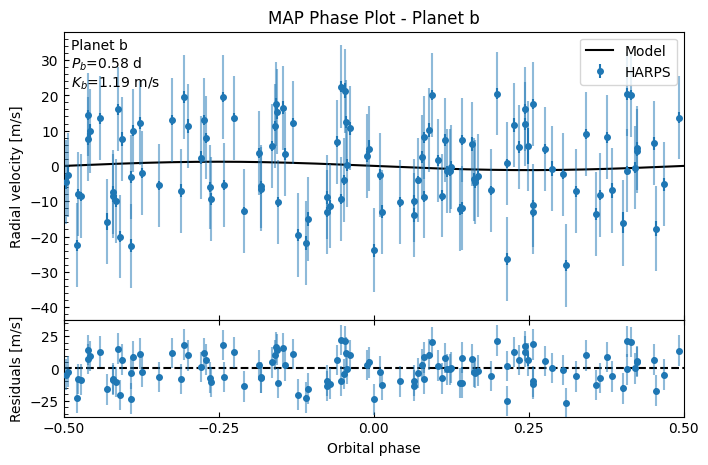
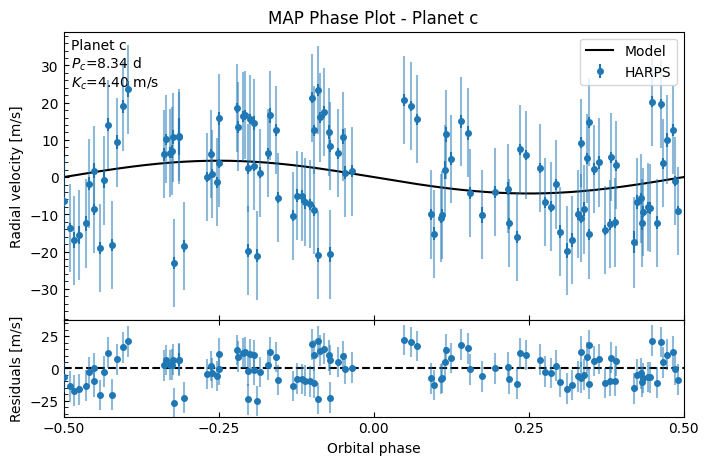
This is a terrible fit! We have contraints on \(P\) and \(T_c\) for both planets from the priors, but even then we can see the system RV still has a correlated pattern in the residuals. This is normally a sign there’s either another potential planet, or there’s strong periodic stellar activity that you’ll want to use a GP to mitigate. Furthermore, on the phase plots, the residual spread is larger than the semi-amplitude of the planet! If we didn’t a priori know there were planets here from transit photometry, then this wouldn’t be a planetary detection at all.
Let’s proceed with MCMC. To speed things up for this notebook, we’ll use the minimum number of walkers (twice the number of free parameters) and we’ll initialise the walkers in a small ball around the MAP values. You’ll definitely want to use more than this (at least one hundred). You could also try initialising the walkers randomly within the full parameter- and prior-space with fitter.generate_initial_walker_positions_random().
nwalkers = 2 * fitter.ndim
mcmc_init = fitter.generate_initial_walker_positions_around_point(centre=map_results.x, nwalkers=nwalkers, verbose=False)
We’ll enable convergence checking: at given intervals through the MCMC, it checks if two criteria are met: first, that the chains are more than 50 times longer than the estimated autocorrelation time for that parameter. Secondly, it checks that the estimate for autocorrelation time is stable (that it hasn’t deviated by more than 1%). This is because the estimate becomes more accurate as you run for longer, so if you don’t check for this you could accidentally stop the MCMC early.
max_steps = 30_000
fitter.run_mcmc(initial_positions=mcmc_init, nwalkers=nwalkers, max_steps=max_steps, progress=True,
multiprocessing=True,
check_convergence=True, convergence_check_interval=1000, convergence_check_start=15000
) # This will take a few minutes!
INFO:root:Starting MCMC with convergence checks. (Maximum 30000 steps, checking convergence every 1000 steps after iteration 15000)...
50%|████▉ | 14977/30000 [00:16<00:16, 918.25it/s] INFO:root:Convergence check: Step 15000: mean(tau)=108.1, max(tau)=144.4
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
53%|█████▎ | 15928/30000 [00:17<00:16, 872.46it/s]INFO:root:Convergence check: Step 16000: mean(tau)=108.7, max(tau)=148.0
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
56%|█████▋ | 16912/30000 [00:18<00:14, 887.48it/s]INFO:root:Convergence check: Step 17000: mean(tau)=107.9, max(tau)=145.0
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
60%|█████▉ | 17922/30000 [00:19<00:12, 990.13it/s]INFO:root:Convergence check: Step 18000: mean(tau)=108.2, max(tau)=144.5
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
63%|██████▎ | 18948/30000 [00:20<00:11, 991.94it/s]INFO:root:Convergence check: Step 19000: mean(tau)=108.4, max(tau)=144.7
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
67%|██████▋ | 19966/30000 [00:22<00:10, 971.78it/s]INFO:root:Convergence check: Step 20000: mean(tau)=108.8, max(tau)=146.0
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
70%|██████▉ | 20985/30000 [00:23<00:09, 986.51it/s]INFO:root:Convergence check: Step 21000: mean(tau)=109.4, max(tau)=147.7
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
73%|███████▎ | 21999/30000 [00:24<00:08, 973.32it/s]INFO:root:Convergence check: Step 22000: mean(tau)=110.1, max(tau)=144.5
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
76%|███████▋ | 22908/30000 [00:25<00:07, 926.54it/s]INFO:root:Convergence check: Step 23000: mean(tau)=109.8, max(tau)=142.9
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
80%|███████▉ | 23913/30000 [00:26<00:06, 963.89it/s]INFO:root:Convergence check: Step 24000: mean(tau)=110.4, max(tau)=145.1
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
83%|████████▎ | 24917/30000 [00:27<00:05, 979.48it/s]INFO:root:Convergence check: Step 25000: mean(tau)=111.0, max(tau)=144.0
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (30000) without convergence! (max tau=144.0, tau stability change=[0.00838535 0.00778386 0.02595902 0.0105206 0.01090875 0.00681828
0.00769988 0.02539886])
86%|████████▋ | 25943/30000 [00:28<00:04, 988.27it/s]INFO:root:Convergence check: Step 26000: mean(tau)=112.0, max(tau)=143.4
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (30000) without convergence! (max tau=143.4, tau stability change=[0.00513445 0.00369911 0.02123724 0.01152862 0.01391231 0.01195421
0.00535025 0.02265637])
90%|████████▉ | 26967/30000 [00:30<00:03, 988.51it/s]INFO:root:Convergence check: Step 27000: mean(tau)=112.0, max(tau)=143.7
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (30000) without convergence! (max tau=143.7, tau stability change=[0.01965712 0.00186869 0.00384083 0.01741703 0.01065352 0.00354651
0.0181409 0.01415842])
93%|█████████▎| 27995/30000 [00:31<00:02, 989.71it/s]INFO:root:Convergence check: Step 28000: mean(tau)=111.6, max(tau)=141.6
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (30000) without convergence! (max tau=141.6, tau stability change=[0.00121576 0.01474897 0.0195424 0.00655147 0.00239235 0.01900221
0.0084498 0.00837733])
96%|█████████▋| 28902/30000 [00:32<00:01, 962.83it/s]INFO:root:Convergence check: Step 29000: mean(tau)=111.8, max(tau)=141.3
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (30000) without convergence! (max tau=141.3, tau stability change=[4.69193998e-03 2.06839580e-03 1.78112484e-02 6.64606253e-05
3.08674164e-03 6.86914449e-03 7.20254389e-04 2.60812691e-04])
100%|█████████▉| 29914/30000 [00:33<00:00, 978.00it/s]INFO:root:Convergence check: Step 30000: mean(tau)=112.5, max(tau)=145.1
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (30000) without convergence! (max tau=145.1, tau stability change=[0.00389084 0.02618315 0.0083381 0.00454228 0.00098418 0.01090259
0.01299852 0.00220816])
100%|██████████| 30000/30000 [00:33<00:00, 885.19it/s]
INFO:root:MCMC complete: 30000 steps total
Let’s take the last 10,000 samples and thin by 10, so that we have 1,000 effective samples per walker.
nburn = fitter.sampler.iteration - 10_000
thin_rate = 10
# Get the samples as a numpy array
samples = fitter.get_samples_np(discard_start=nburn, discard_end=0, thin=thin_rate, flat=False) # shape (nsteps, nwalkers, ndim)
fitter.plot_chains(discard_start=nburn, discard_end=0, thin=thin_rate, save=False)
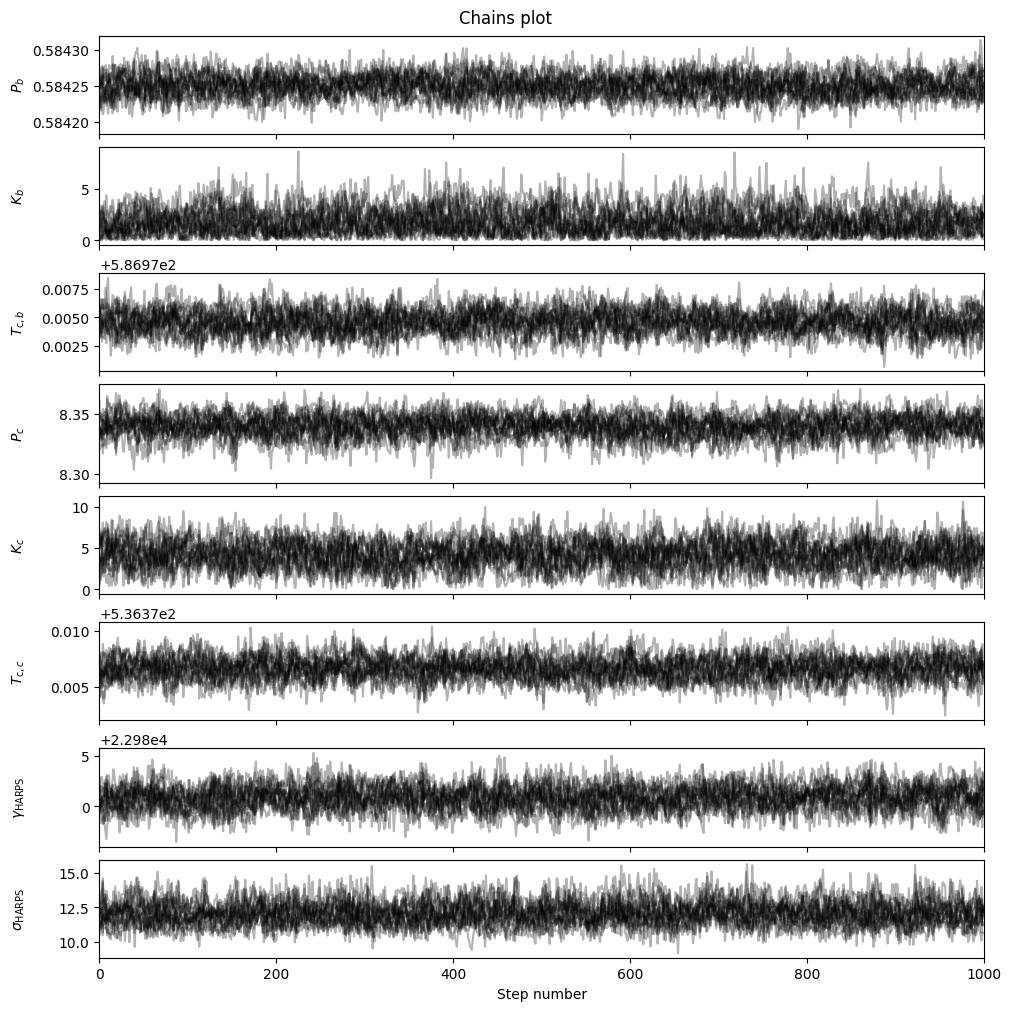
fitter.plot_corner(discard_start=nburn, discard_end=0, thin=thin_rate, plot_datapoints=True, save=False)
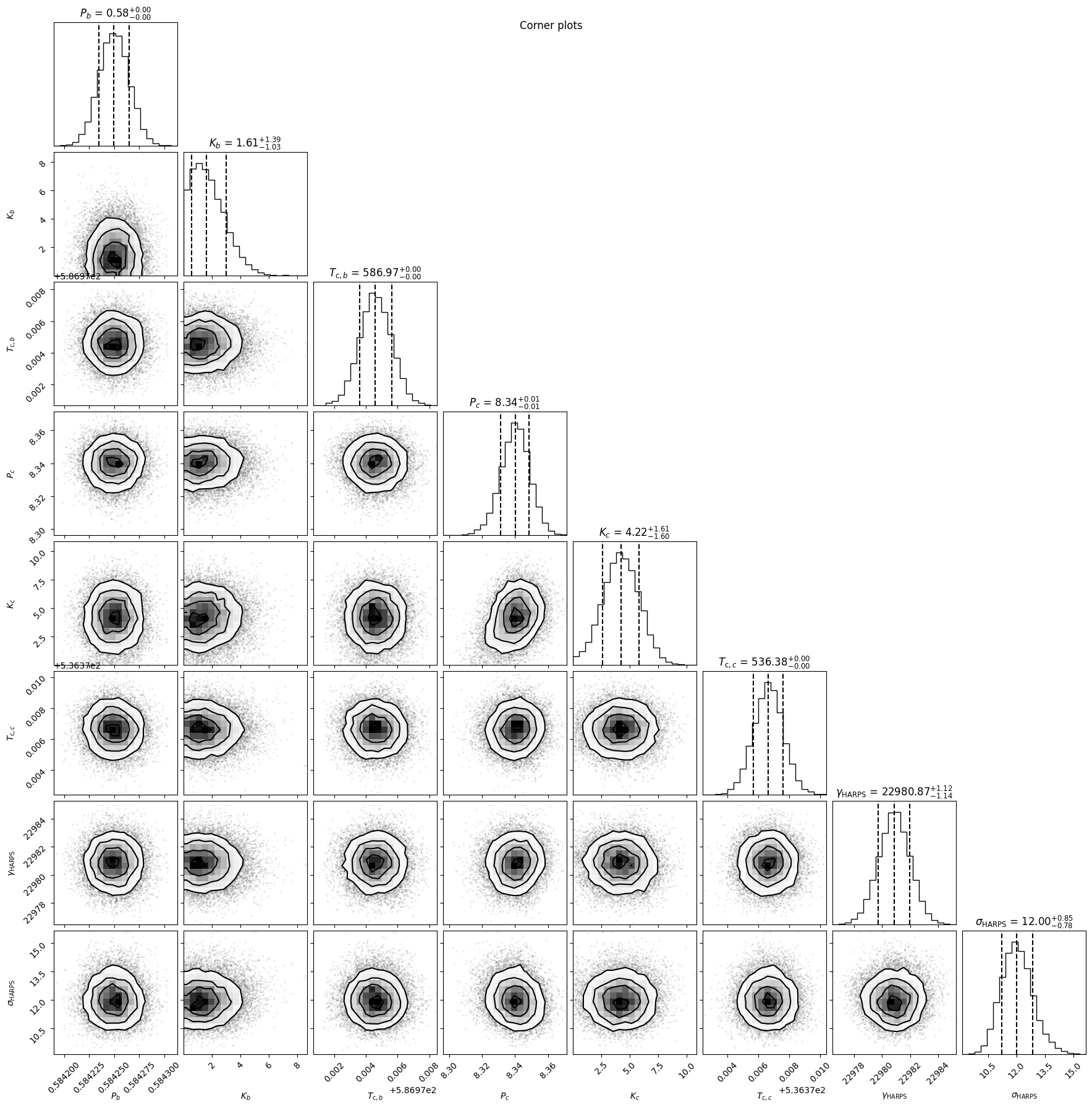
The parameter distributions shown in the chains and corner plots look well-behaved (converged, more-or-less Normal distributions), but this is misleading - recall that the actual fit to the data (after the MAP optimisation) was poor. We can plot the posterior RV and Phase plots using our MCMC samples to check this:
# Use more aggressive thinning for RV/phase plots as they're computationally expensive
plot_thin = thin_rate * 10
fitter.plot_posterior_rv(discard_start=nburn, discard_end=0, thin=plot_thin)
fitter.plot_posterior_phase("b", discard_start=nburn, discard_end=0, thin=plot_thin)
fitter.plot_posterior_phase("c", discard_start=nburn, discard_end=0, thin=plot_thin)
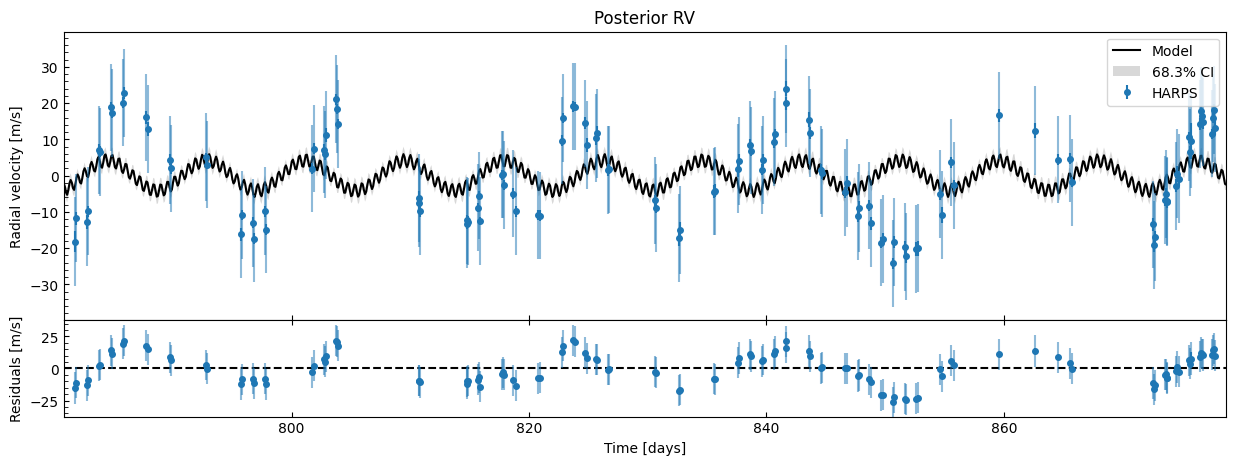
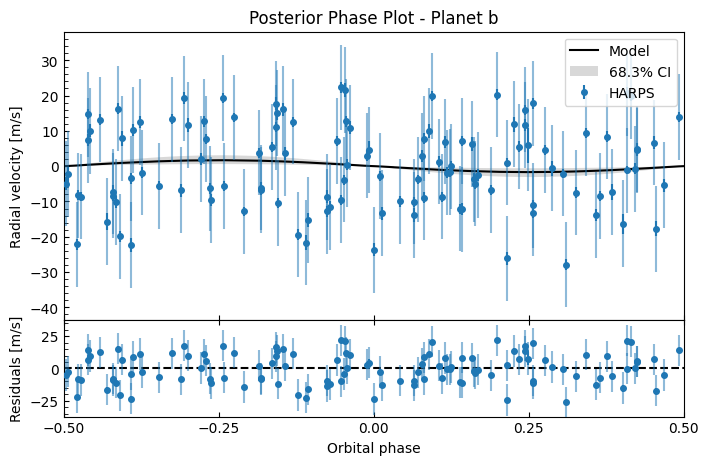
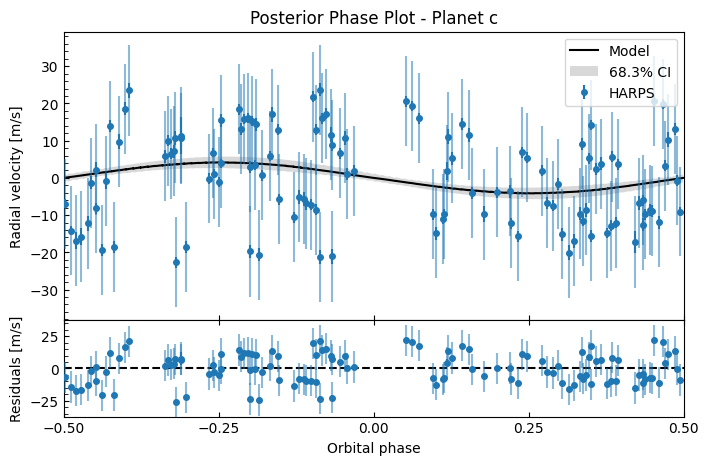
Again, it’s a terrible fit! This confirms that it wasn’t just that the MAP failed to reach a good solution (which can happen), it shows that even across the posterior MCMC samples, the fit is consistently terrible, suggesting this white-noise model isn’t suitable here. The correlated residuals indicate we should use a GP to model stellar activity.
We can quickly look at the final parameter values for each parameter’s marginalised posterior distribution (say, the 50th percentile/median of each parameter’s flattened chains) and compute some quick summary statistics of our fit so we can compare it with the GP fit later.
# For the non-GP Fitter
print("Results for Fitter (white noise model)")
# Get flattened samples (with the same discard and thinning)
fitter_samples = fitter.get_samples_np(discard_start=nburn, discard_end=0, thin=10, flat=True)
# Calculate 50th percentile for each free parameter
fitter_medians = np.percentile(fitter_samples, 50, axis=0)
print(f"\nMedian free parameter values:")
for name, value in zip(fitter.free_params_names, fitter_medians):
print(f" {name}: {value}")
Results for Fitter (white noise model)
Median free parameter values:
P_b: 0.5842496754953359
K_b: 1.6144464495111097
Tc_b: 586.974586794789
P_c: 8.340155124121935
K_c: 4.217744167198635
Tc_c: 536.3766537548663
g_HARPS: 22980.872630898448
jit_HARPS: 12.00029829477958
# Build complete params dict (combines free params with fixed params)
fitter_complete_dict = fitter.build_params_dict(fitter_medians)
fitter_complete_dict
{'e_b': 0,
'w_b': 1.5707963267948966,
'e_c': 0,
'w_c': 1.5707963267948966,
'gd': 0,
'gdd': 0,
'P_b': np.float64(0.5842496754953359),
'K_b': np.float64(1.6144464495111097),
'Tc_b': np.float64(586.974586794789),
'P_c': np.float64(8.340155124121935),
'K_c': np.float64(4.217744167198635),
'Tc_c': np.float64(536.3766537548663),
'g_HARPS': np.float64(22980.872630898448),
'jit_HARPS': np.float64(12.00029829477958)}
We can calculate a few metrics for the white-noise model to see how (badly) it has performed:
# Calculate metrics
fitter_chi2 = fitter.calculate_chi2(fitter_complete_dict)
fitter_loglike = fitter.calculate_log_likelihood(fitter_complete_dict)
fitter_aicc = fitter.calculate_aicc(fitter_complete_dict) # corrected Akaike Information Criterion
fitter_bic = fitter.calculate_bic(fitter_complete_dict) # Bayesian Information Criterion
print(f"Metrics at 50th percentile:")
print(f"Chi^2: {fitter_chi2:.2f}")
print(f"Log-likelihood: {fitter_loglike:.2f}")
print(f"AICc: {fitter_aicc:.2f}")
print(f"BIC: {fitter_bic:.2f}")
Metrics at 50th percentile:
Chi^2: 115.49
Log-likelihood: -467.42
AICc: 952.13
BIC: 973.14
Fitting with a Gaussian Process
I’m assuming some familiarity with Gaussian Processes here; if not then I recommend the excellent review article Aigrain & Foreman-Mackey 2023 as a starting point.
To use a GP in Ravest, we use the GPFitter class. The interface to this is very similar to the Fitter class we just used, but with some extra steps to set up the GP kernel and its hyperparameters and hyperpriors.
from ravest.fit import GPFitter
from ravest.gp import GPKernel
We will use the Quasiperiodic Kernel as defined by Roberts et al. 2013 (with slightly different notation):
where \(A\) is the GP amplitude, \(P_\text{GP}\) and \(\lambda_p\) are the period and length scale of the periodic component, and \(\lambda_e\) is the evolutionary timescale.
gpkernel = GPKernel(kernel_type="Quasiperiodic")
gpkernel.get_expected_hyperparams()
['gp_amp', 'gp_lambda_e', 'gp_lambda_p', 'gp_period']
parameterisation=Parameterisation("P K e w Tc")
gpfitter = GPFitter(planet_letters=["b","c"], parameterisation=parameterisation,
gp_kernel=gpkernel)
gpfitter.add_data(
time=(data["BJD"].to_numpy()-2457000),
vel=data["RV"].to_numpy(),
velerr=data["e_RV"].to_numpy(),
instrument=data["tel"].to_numpy(),
t0=np.mean(data["BJD"].to_numpy()-2457000),
)
For the planetary/system parameters, we’ll use the same parameters and priors as before.
gpfitter.params = params
gpfitter.params
{'P_b': Parameter(value=0.584249, unit='d', fixed=False),
'K_b': Parameter(value=10, unit='m/s', fixed=False),
'e_b': Parameter(value=0, unit='', fixed=True),
'w_b': Parameter(value=1.5707963267948966, unit='', fixed=True),
'Tc_b': Parameter(value=586.9750000000931, unit='d', fixed=False),
'P_c': Parameter(value=8.32835, unit='d', fixed=False),
'K_c': Parameter(value=10, unit='m/s', fixed=False),
'e_c': Parameter(value=0, unit='', fixed=True),
'w_c': Parameter(value=1.5707963267948966, unit='', fixed=True),
'Tc_c': Parameter(value=536.3646999998018, unit='d', fixed=False),
'g_HARPS': Parameter(value=np.float64(22981.045158814868), unit='m/s', fixed=False),
'gd': Parameter(value=0, unit='m/s/day', fixed=True),
'gdd': Parameter(value=0, unit='m/s/day^2', fixed=True),
'jit_HARPS': Parameter(value=0.01, unit='m/s', fixed=False)}
gpfitter.priors = priors
gpfitter.priors
{'P_b': Normal(mean=0.58425, std=1.5e-05),
'K_b': Uniform(lower=0, upper=100),
'Tc_b': Normal(mean=586.9746, std=0.001),
'P_c': Normal(mean=8.3274, std=0.01),
'K_c': Uniform(lower=0, upper=100),
'Tc_c': Normal(mean=536.3766, std=0.001),
'g_HARPS': Uniform(lower=22932.870701387474, upper=23029.219616242262),
'jit_HARPS': Uniform(lower=0, upper=100)}
Now we need to set the hyperparameters and their hyperpriors for the GP Kernel. Again in the interests of making this converge quickly so the notebook runs quickly, we adopt the published values from Santerne et al. 2018 for the hyperparameters.
hyperparams = {
"gp_amp": Parameter(value=12.3, unit="", fixed=False),
"gp_lambda_e": Parameter(value=16.7, unit="d", fixed=False),
"gp_lambda_p": Parameter(value=0.71, unit="", fixed=False),
"gp_period": Parameter(value=18.2, unit="d", fixed=False),
}
gpfitter.hyperparams = hyperparams
gpfitter.hyperparams
{'gp_amp': Parameter(value=12.3, unit='', fixed=False),
'gp_lambda_e': Parameter(value=16.7, unit='d', fixed=False),
'gp_lambda_p': Parameter(value=0.71, unit='', fixed=False),
'gp_period': Parameter(value=18.2, unit='d', fixed=False)}
# Hyperpriors from Santerne et al. 2018 Nature paper supplementary table 6
hyperpriors = {
"gp_amp": ravest.prior.Uniform(0, 100),
"gp_lambda_e": ravest.prior.Normal(16.7, 2.5),
"gp_lambda_p": ravest.prior.Normal(0.71, 0.12),
"gp_period": ravest.prior.Normal(18.2, 0.3),
}
gpfitter.hyperpriors = hyperpriors
gpfitter.hyperpriors
{'gp_amp': Uniform(lower=0, upper=100),
'gp_lambda_e': Normal(mean=16.7, std=2.5),
'gp_lambda_p': Normal(mean=0.71, std=0.12),
'gp_period': Normal(mean=18.2, std=0.3)}
gpmap_results = gpfitter.find_map_estimate(method="Powell")
gpmap_results
INFO:2026-03-01 00:40:30,942:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
MAP parameter results: {'P_b': np.float64(0.5842510463066862), 'K_b': np.float64(2.1373375534764407), 'Tc_b': np.float64(586.9746150640128), 'P_c': np.float64(8.32841618649488), 'K_c': np.float64(2.5761956969575475), 'Tc_c': np.float64(536.3766003076861), 'g_HARPS': np.float64(22980.8098207897), 'jit_HARPS': np.float64(1.6778677934003081)}
MAP hyperparameter results: {'gp_amp': np.float64(12.294561087495767), 'gp_lambda_e': np.float64(17.202054442177236), 'gp_lambda_p': np.float64(0.41777006632275115), 'gp_period': np.float64(18.39520232553368)}
message: Optimization terminated successfully.
success: True
status: 0
fun: 338.25218425887044
x: [ 5.843e-01 2.137e+00 5.870e+02 8.328e+00 2.576e+00
5.364e+02 2.298e+04 1.678e+00 1.229e+01 1.720e+01
4.178e-01 1.840e+01]
nit: 5
direc: [[ 1.000e+00 0.000e+00 ... 0.000e+00 0.000e+00]
[ 0.000e+00 1.000e+00 ... 0.000e+00 0.000e+00]
...
[ 0.000e+00 0.000e+00 ... 1.000e+00 0.000e+00]
[-2.202e-07 2.455e-02 ... -4.034e-02 -2.622e-02]]
nfev: 623
gpfitter.plot_MAP_rv(map_result=gpmap_results)
gpfitter.plot_MAP_phase(planet_letter="b", map_result=gpmap_results)
gpfitter.plot_MAP_phase(planet_letter="c", map_result=gpmap_results)
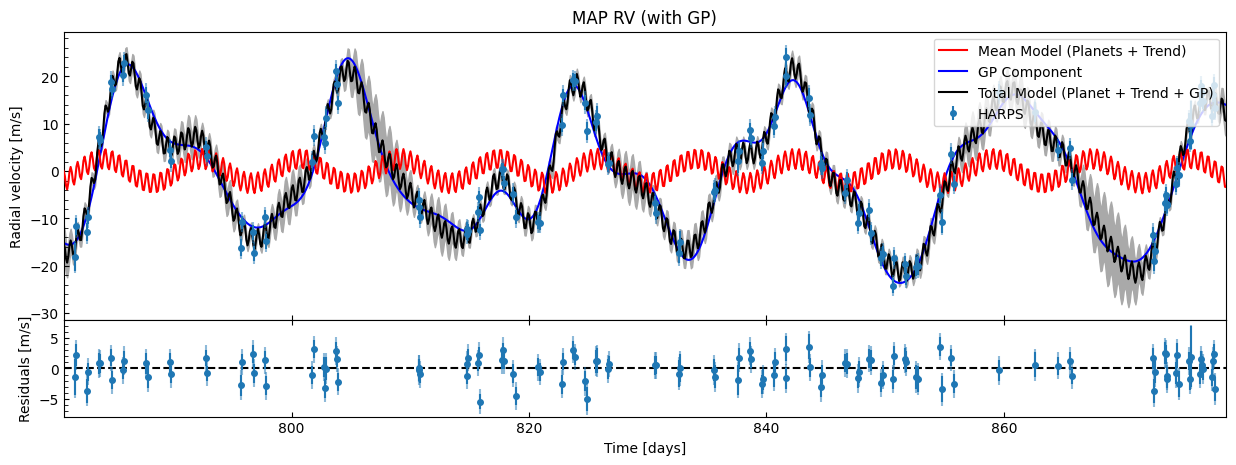
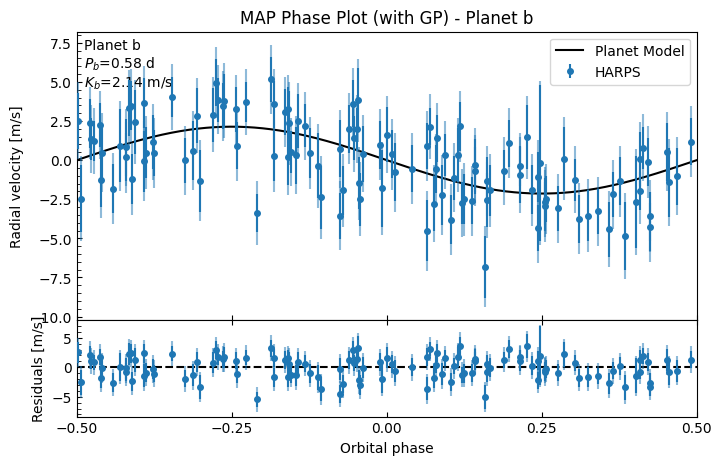
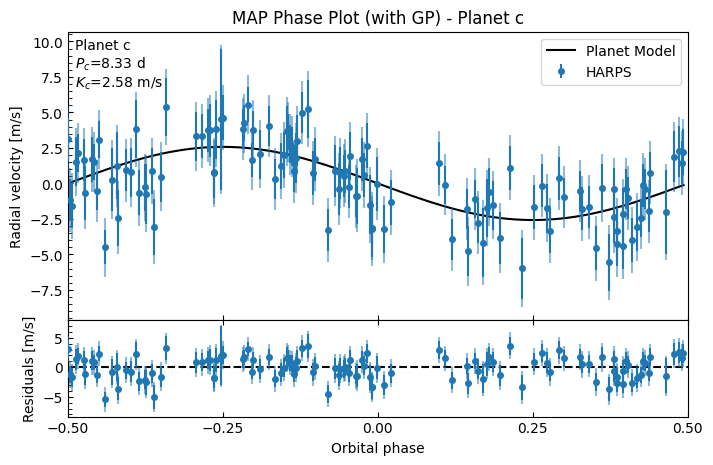
This looks a lot better! The GP has fitted to the correlated noise well. The system RV residuals no longer look correlated (it now looks like white noise), and the planetary phase plots look much better.
Let’s start MCMC. Again we will run this for the minimum number of walkers (two times the number of free parameters) initalised in a ball around the MAP results, and only run for a small number of steps so that this notebook runs quickly. You should definitely use more walkers and steps!
nwalkers = 2 * gpfitter.ndim
mcmc_init = gpfitter.generate_initial_walker_positions_around_point(centre=gpmap_results.x, nwalkers=nwalkers, verbose=False)
# Fit the free parameters to the data. Use the MAP solution as the initial value for the MCMC walkers.
gpfitter.run_mcmc(initial_positions=mcmc_init,
nwalkers=nwalkers, max_steps=20_000, progress=True,
multiprocessing=True,
check_convergence=True, convergence_check_interval=1000, convergence_check_start=15000
) # This will take a few minutes!
INFO:root:Starting MCMC with convergence checks. (Maximum 20000 steps, checking convergence every 1000 steps after iteration 15000)...
INFO:2026-03-01 00:40:35,861:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:35,932:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:35,944:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,004:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,022:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,028:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,039:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,040:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,051:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:2026-03-01 00:40:36,058:jax._src.xla_bridge:810: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
INFO:jax._src.xla_bridge:Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
75%|███████▍ | 14998/20000 [02:37<00:50, 99.28it/s] INFO:root:Convergence check: Step 15000: mean(tau)=176.1, max(tau)=219.5
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
80%|███████▉ | 15994/20000 [02:47<00:40, 98.57it/s] INFO:root:Convergence check: Step 16000: mean(tau)=178.0, max(tau)=219.1
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
85%|████████▍ | 16994/20000 [02:57<00:29, 100.55it/s]INFO:root:Convergence check: Step 17000: mean(tau)=177.8, max(tau)=214.0
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (20000) without convergence! (max tau=214.0, tau stability change=[0.01527429 0.0195698 0.01542276 0.01996161 0.01647563 0.00448251
0.00099318 0.00643967 0.02423663 0.0245666 0.01690899 0.00484497])
90%|████████▉ | 17995/20000 [03:08<00:19, 104.24it/s]INFO:root:Convergence check: Step 18000: mean(tau)=177.4, max(tau)=218.3
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (20000) without convergence! (max tau=218.3, tau stability change=[0.00208342 0.00140914 0.02078163 0.0061427 0.01291982 0.02655369
0.04438755 0.0101016 0.01994404 0.01121111 0.00150497 0.00822318])
95%|█████████▍| 18993/20000 [03:18<00:09, 103.45it/s]INFO:root:Convergence check: Step 19000: mean(tau)=178.2, max(tau)=218.6
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (20000) without convergence! (max tau=218.6, tau stability change=[0.00738867 0.00528473 0.02938931 0.01322128 0.00583494 0.00837293
0.00352678 0.03060155 0.00147002 0.02754596 0.01932485 0.01384097])
100%|█████████▉| 19997/20000 [03:28<00:00, 104.20it/s]INFO:root:Convergence check: Step 20000: mean(tau)=178.3, max(tau)=218.2
INFO:root:Not yet converged (N/50>tau check: True, tau stability check: False)
WARNING:root:Approaching max iterations (20000) without convergence! (max tau=218.2, tau stability change=[0.01384355 0.00300775 0.03497224 0.01391627 0.00817893 0.02302064
0.00108556 0.00172769 0.00210306 0.0106768 0.01094895 0.00980015])
100%|██████████| 20000/20000 [03:28<00:00, 95.81it/s]
INFO:root:MCMC complete: 20000 steps total
gpfitter.plot_autocorr_estimates()
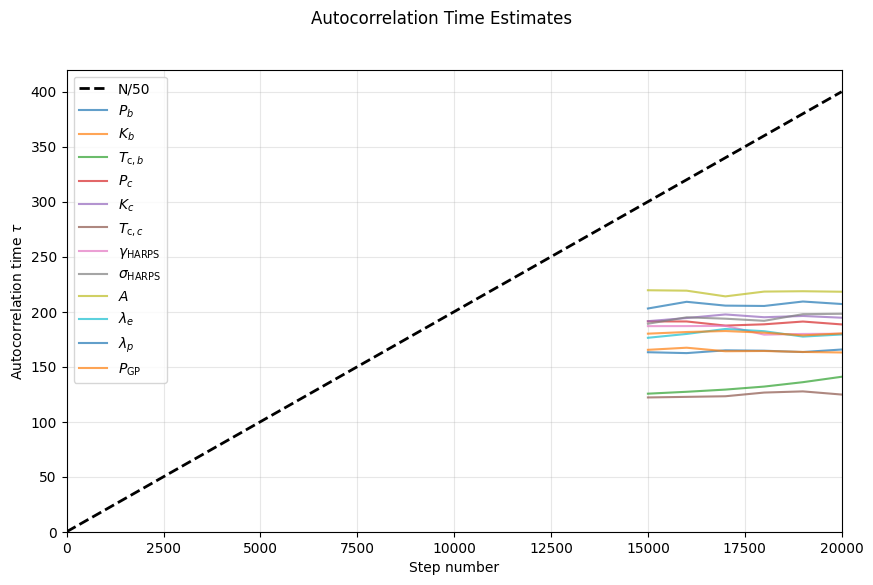
Looking at the autocorrelation estimate plot, we can consider these chains converged as the chains are all considerably longer then 50 times the estimated autocorrelation time (below the dashed line), and the estimates look stable (even if they didn’t quite meet the formal \(\Delta{\tau}<1\)% stability criterion).
Again we’ll take the last 10,000 iterations and thin by 10, to have 1,000 effective samples per walker.
nburn = gpfitter.sampler.iteration - 10_000
# Get the samples as a numpy array
gpsamples = gpfitter.get_samples_np(discard_start=nburn, discard_end=0, thin=thin_rate, flat=False) # shape (nsteps, nwalkers, ndim)
# Get the samples as a labelled Pandas dataframe
gpsamples_df = gpfitter.get_samples_df(discard_start=nburn, discard_end=0, thin=10) # shape (nsteps*nwalkers, ndim)
gpsamples_df
| P_b | K_b | Tc_b | P_c | K_c | Tc_c | g_HARPS | jit_HARPS | gp_amp | gp_lambda_e | gp_lambda_p | gp_period | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.584249 | 2.055678 | 586.974246 | 8.335803 | 0.782498 | 536.377843 | 22983.644296 | 2.409283 | 17.115899 | 17.727281 | 0.474016 | 18.054111 |
| 1 | 0.584247 | 2.647269 | 586.975546 | 8.323970 | 2.215120 | 536.375747 | 22980.055382 | 1.913694 | 16.971365 | 18.215271 | 0.514310 | 18.576327 |
| 2 | 0.584271 | 2.399962 | 586.973864 | 8.332002 | 2.216903 | 536.378734 | 22978.390036 | 2.068474 | 12.037737 | 16.231491 | 0.435962 | 18.700645 |
| 3 | 0.584232 | 2.619956 | 586.974932 | 8.331727 | 0.190668 | 536.377586 | 22979.871819 | 1.711087 | 9.302204 | 17.939440 | 0.260200 | 18.445059 |
| 4 | 0.584260 | 1.717799 | 586.974629 | 8.323339 | 4.875172 | 536.376241 | 22978.294827 | 1.955064 | 12.009517 | 17.856300 | 0.393266 | 17.962948 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 23995 | 0.584271 | 2.184247 | 586.975226 | 8.328377 | 0.008339 | 536.376429 | 22984.835862 | 1.927418 | 18.297145 | 22.927270 | 0.581375 | 18.305667 |
| 23996 | 0.584266 | 2.193548 | 586.975651 | 8.324033 | 3.982343 | 536.375500 | 22985.989535 | 1.742489 | 10.571839 | 16.269029 | 0.418371 | 18.053188 |
| 23997 | 0.584244 | 1.811261 | 586.973710 | 8.336204 | 5.493147 | 536.376015 | 22978.914190 | 2.135226 | 11.618486 | 19.209337 | 0.388503 | 18.297677 |
| 23998 | 0.584243 | 1.950121 | 586.974748 | 8.307392 | 0.717866 | 536.377272 | 22986.013557 | 2.232271 | 14.711024 | 20.389894 | 0.500950 | 18.731381 |
| 23999 | 0.584239 | 2.685421 | 586.975284 | 8.333340 | 1.968927 | 536.376252 | 22982.548604 | 2.223424 | 10.829192 | 18.167565 | 0.448800 | 18.612900 |
24000 rows × 12 columns
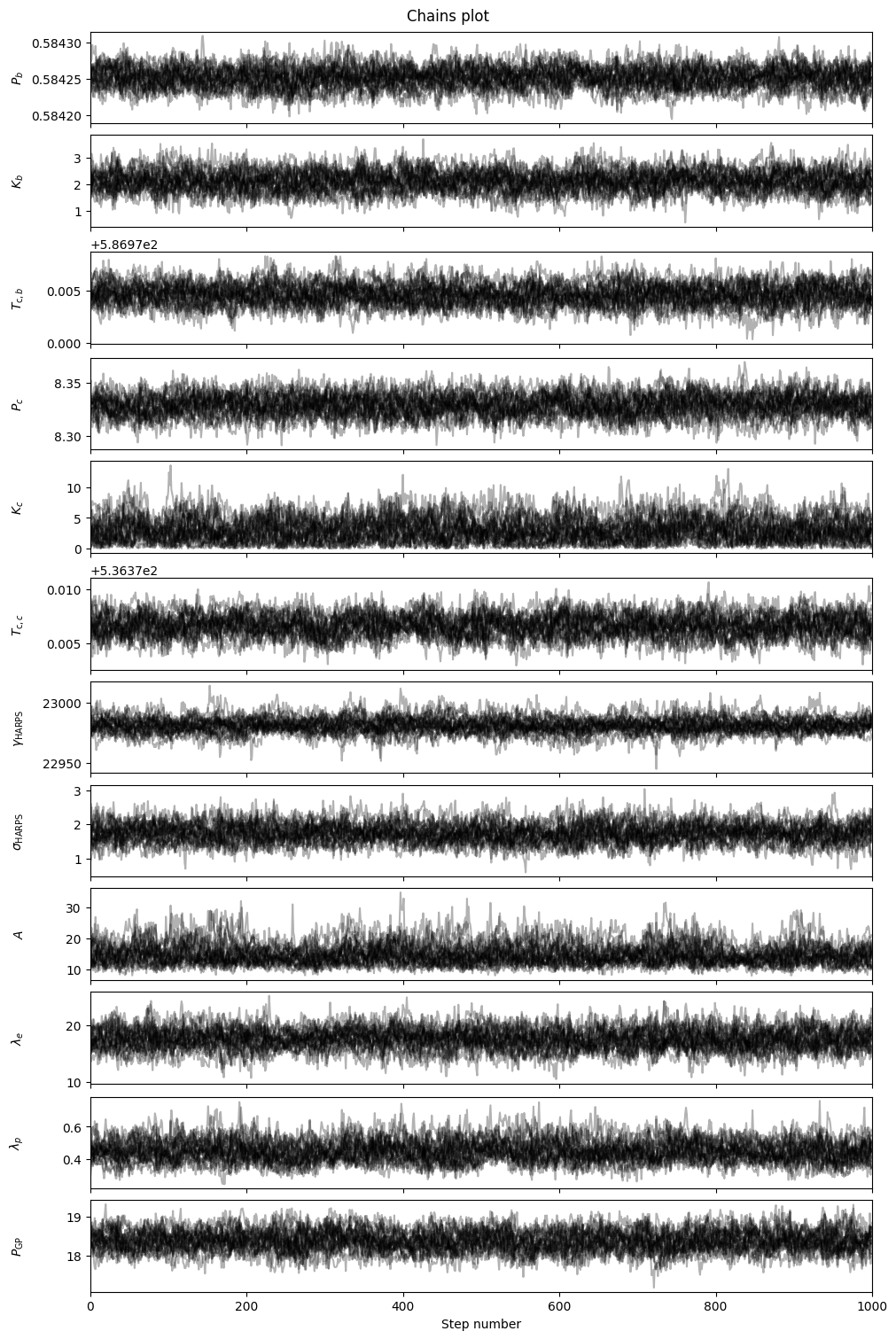
gpfitter.plot_chains(discard_start=nburn, discard_end=0, thin=thin_rate, save=False)
gpfitter.plot_corner(discard_start=nburn, discard_end=0, thin=thin_rate, plot_datapoints=True, save=False,)
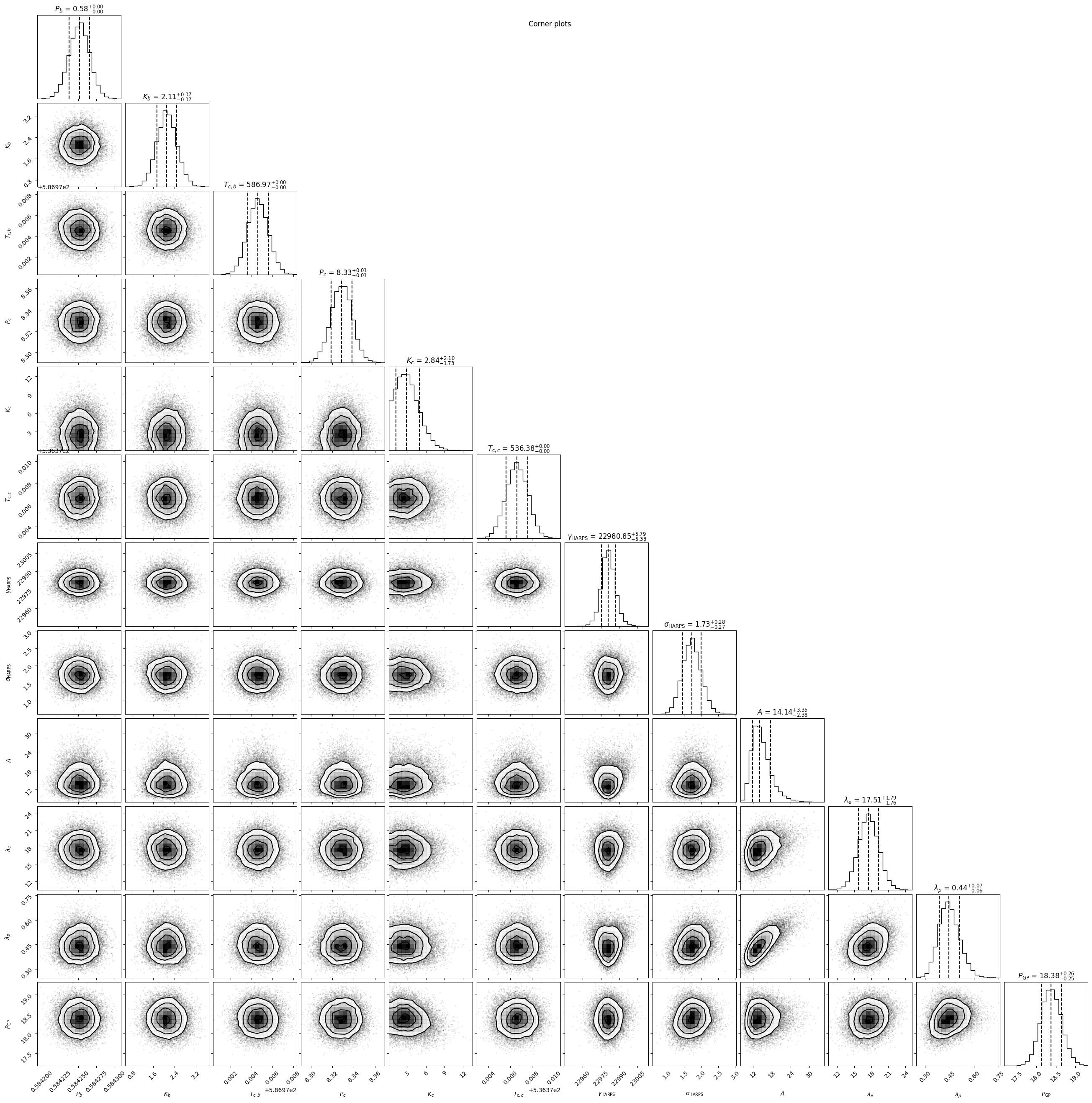
Chains and corners look good (unsurprising given the tight priors we imposed!) It’s not uncommon for GP hyperparameters to be multi-modal , if you encounter this then you may want to reconsider your choices of priors.
Let’s look at the posterior RV and phase plots, with the GP’s 1-\(\sigma\) uncertainty plotted too. Again we 10x the thin rate here because these plots can take a while due to all the GP evaluations required from each sample.
# Use more aggressive thinning for RV/phase plots
plot_thin = thin_rate * 10
gpfitter.plot_posterior_rv(discard_start=nburn, discard_end=0, thin=plot_thin)
Processing 2400 effective samples (after discard_start=10000, discard_end=0, thin=100)
Calculating planet b RV at 120 observed times...
Calculating planet b RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 45542.61it/s]
Calculating planet b RV at 1000 smooth times...
Calculating planet b RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 56853.29it/s]
Calculating planet c RV at 120 observed times...
Calculating planet c RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 88229.93it/s]
Calculating planet c RV at 1000 smooth times...
Calculating planet c RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 65409.52it/s]
Calculating trend RV at 120 observed times...
Calculating trend RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 125150.18it/s]
Calculating trend RV at 1000 smooth times...
Calculating trend RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 85923.18it/s]
Computing GP predictions: 100%|██████████| 2400/2400 [00:59<00:00, 40.44it/s]
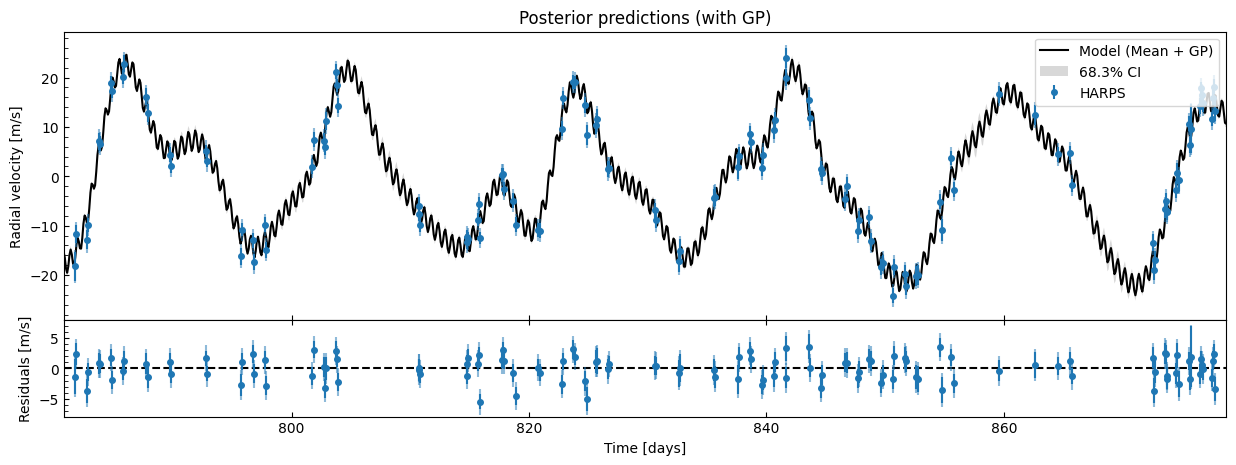
gpfitter.plot_posterior_phase("b", discard_start=nburn, discard_end=0, thin=plot_thin)
Processing 2400 effective samples (after discard_start=10000, discard_end=0, thin=100)
Calculating planet b RV at 120 observed times...
Calculating planet b RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 54102.60it/s]
Calculating planet b RV at 50 smooth times...
Calculating planet b RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 84864.85it/s]
Calculating planet c RV at 120 observed times...
Calculating planet c RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 84021.92it/s]
Calculating trend RV at 120 observed times...
Calculating trend RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 119958.64it/s]
100%|██████████| 2400/2400 [00:27<00:00, 87.13it/s]
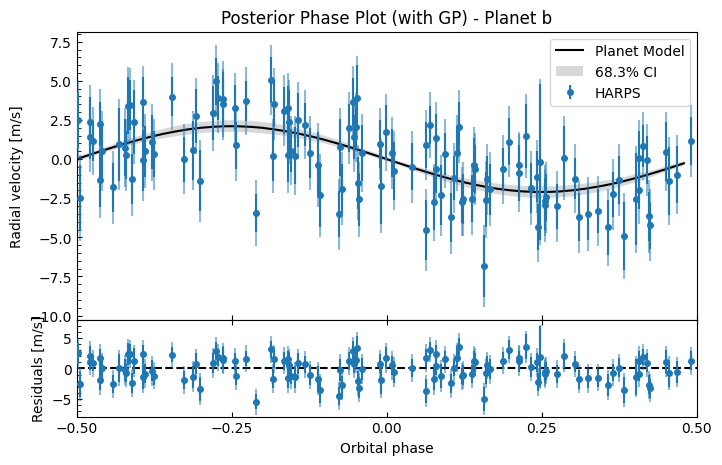
gpfitter.plot_posterior_phase("c", discard_start=nburn, discard_end=0, thin=plot_thin)
Processing 2400 effective samples (after discard_start=10000, discard_end=0, thin=100)
Calculating planet c RV at 120 observed times...
Calculating planet c RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 86987.92it/s]
Calculating planet c RV at 50 smooth times...
Calculating planet c RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 91143.37it/s]
Calculating planet b RV at 120 observed times...
Calculating planet b RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 89792.16it/s]
Calculating trend RV at 120 observed times...
Calculating trend RV from samples: 100%|██████████| 2400/2400 [00:00<00:00, 125154.85it/s]
100%|██████████| 2400/2400 [00:27<00:00, 87.45it/s]
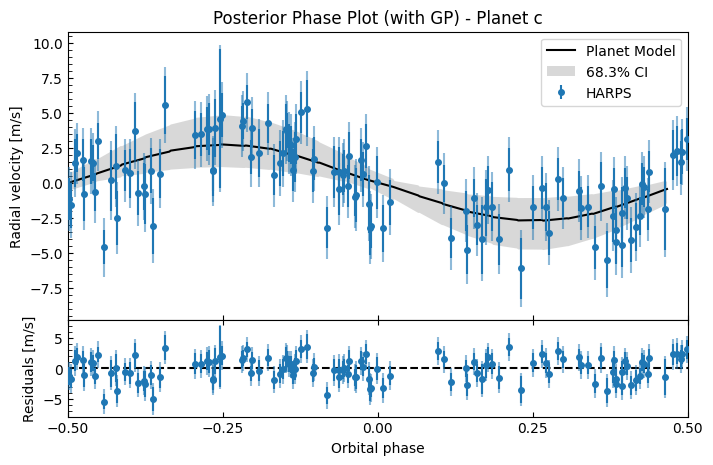
# For the GPFitter
print("Results for GPFitter (with Gaussian Process)")
# Get flattened samples (discard burn-in)
gpfitter_samples = gpfitter.get_samples_np(discard_start=nburn, discard_end=0, thin=1, flat=True)
# Calculate 50th percentile for each free parameter and hyperparameter
gpfitter_medians = np.percentile(gpfitter_samples, 50, axis=0)
print(f"\nMedian free parameter/hyperparameter values:")
all_names = gpfitter.free_params_names + gpfitter.free_hyperparams_names
for name, value in zip(all_names, gpfitter_medians):
print(f" {name}: {value}")
Results for GPFitter (with Gaussian Process)
Median free parameter/hyperparameter values:
P_b: 0.5842517060797564
K_b: 2.112002362776714
Tc_b: 586.974620341704
P_c: 8.328765425129081
K_c: 2.8354458512181804
Tc_c: 536.3766081945815
g_HARPS: 22980.856241583984
jit_HARPS: 1.7300431536041363
gp_amp: 14.14373893712125
gp_lambda_e: 17.511862425648992
gp_lambda_p: 0.44425505520849073
gp_period: 18.37882253700921
# Build complete params+hyperparams dict
gpfitter_complete_dict = gpfitter.build_params_dict(gpfitter_medians)
gpfitter_complete_dict
{'e_b': 0,
'w_b': 1.5707963267948966,
'e_c': 0,
'w_c': 1.5707963267948966,
'gd': 0,
'gdd': 0,
'P_b': np.float64(0.5842517060797564),
'K_b': np.float64(2.112002362776714),
'Tc_b': np.float64(586.974620341704),
'P_c': np.float64(8.328765425129081),
'K_c': np.float64(2.8354458512181804),
'Tc_c': np.float64(536.3766081945815),
'g_HARPS': np.float64(22980.856241583984),
'jit_HARPS': np.float64(1.7300431536041363),
'gp_amp': np.float64(14.14373893712125),
'gp_lambda_e': np.float64(17.511862425648992),
'gp_lambda_p': np.float64(0.44425505520849073),
'gp_period': np.float64(18.37882253700921)}
We can calculate the same performance metrics that we did earlier for the white-noise model:
# Calculate metrics
gpfitter_chi2 = gpfitter.calculate_chi2(gpfitter_complete_dict)
gpfitter_loglike = gpfitter.calculate_log_likelihood(gpfitter_complete_dict)
gpfitter_aicc = gpfitter.calculate_aicc(gpfitter_complete_dict) # corrected Akaike Information Criterion
gpfitter_bic = gpfitter.calculate_bic(gpfitter_complete_dict) # Bayesian Information Criterion
print(f"\nMetrics at 50th percentile:")
print(f" Chi^2: {gpfitter_chi2:.2f}")
print(f" Log-likelihood: {gpfitter_loglike:.2f}")
print(f" AICc: {gpfitter_aicc:.2f}")
print(f" BIC: {gpfitter_bic:.2f}")
Metrics at 50th percentile:
Chi^2: 111.15
Log-likelihood: -338.39
AICc: 703.69
BIC: 734.22
Model Comparison
Now let’s compare the two models quantitatively using the metrics we’ve calculated. While visual inspection of the residuals clearly shows the GP model fits better, we can use statistical metrics to quantify this improvement.
print(f"\n{'Metric':<20} {'No GP':>12} {'GP':>12} {'':>20}")
print("-" * 70)
print(f"{'Free parameters':<20} {fitter.ndim:>12} {gpfitter.ndim:>12}")
print(f"{'Chi2':<20} {fitter_chi2:>12.2f} {gpfitter_chi2:>12.2f} {'(lower is better)':>20}")
print(f"{'Log-likelihood':<20} {fitter_loglike:>12.2f} {gpfitter_loglike:>12.2f} {'(higher is better)':>20}")
print(f"{'AICc':<20} {fitter_aicc:>12.2f} {gpfitter_aicc:>12.2f} {'(lower is better)':>20}")
print(f"{'BIC':<20} {fitter_bic:>12.2f} {gpfitter_bic:>12.2f} {'(lower is better)':>20}")
Metric No GP GP
----------------------------------------------------------------------
Free parameters 8 12
Chi2 115.49 111.15 (lower is better)
Log-likelihood -467.42 -338.39 (higher is better)
AICc 952.13 703.69 (lower is better)
BIC 973.14 734.22 (lower is better)
We can see that in all four metrics, the GP model is preferred, even with AIC and BIC where the GP model gets penalised for having 4 additional free parameters.