K2-24
RadVel and exoplanet both have excellent tutorials where they fit for the two planets b and c of the K2-24 system. We will do the same here to show how to fit RV data in Ravest.
Links:
K2-24 paper (Petigura et al 2016 ApJ 818 36): https://doi.org/10.3847/0004-637X/818/1/36
RadVel tutorial: https://radvel.readthedocs.io/en/latest/tutorials/K2-24_Fitting+MCMC.html
exoplanet tutorial: https://gallery.exoplanet.codes/tutorials/rv/
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import ravest.prior
from ravest.fit import Fitter
from ravest.model import calculate_mpsini
from ravest.param import Parameter, Parameterisation
Import the data
fpath = Path.cwd() / "example_data" / "K2-24.csv"
data = pd.read_csv(fpath)
data.head()
| errvel | time | vel | tel | |
|---|---|---|---|---|
| 0 | 1.593725 | 2364.819580 | 6.959066 | HIRES |
| 1 | 1.600745 | 2364.825101 | 5.017650 | HIRES |
| 2 | 1.658815 | 2364.830703 | 13.811799 | HIRES |
| 3 | 1.653224 | 2366.827579 | 1.151030 | HIRES |
| 4 | 1.639095 | 2367.852646 | 9.389273 | HIRES |
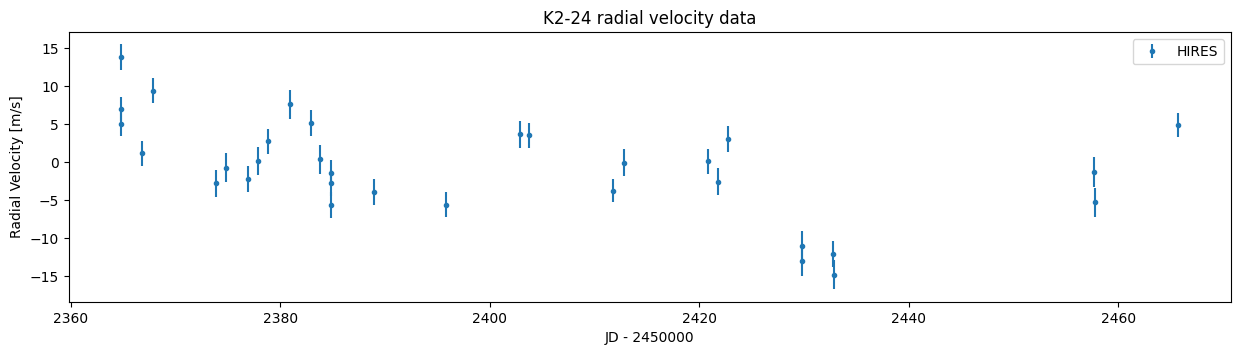
plt.figure(figsize=(15,3.5))
plt.title("K2-24 radial velocity data")
plt.ylabel("Radial Velocity [m/s]")
plt.xlabel("JD - 2450000")
plt.errorbar(data["time"], data["vel"], yerr=data["errvel"], marker=".", label="HIRES", linestyle="None")
plt.legend()
plt.show()
Circular orbits
Create a Fitter object, and choose which parameterisation to fit with, whether to fix or fit for each parameter, and the initial parameter values. We can fit a circular model by fixing eccentricity \(e=0\) (the argument of periapsis \(\omega_\star\) is now degenerate and can be fixed at any value, by convention we fix at \(\pi/2\).) The reference zero-point time t0 is used for linear and quadratic trends terms \(\dot{\gamma}\) and \(\ddot{\gamma}\).
fitter = Fitter(planet_letters=["b","c"], parameterisation=Parameterisation("P K e w Tc"))
fitter.add_data(time=data["time"].to_numpy(),
vel=data["vel"].to_numpy(),
velerr=data["errvel"].to_numpy(),
instrument=data["tel"].to_numpy(),
t0=2420)
# Construct the params dict
# These values will be used as your initial guess for the fit
params = {"P_b": Parameter(20.8853, "d", fixed=True),
"K_b": Parameter(10, "m/s", fixed=False),
"e_b": Parameter(0, "", fixed=True),
"w_b": Parameter(np.pi/2, "rad", fixed=True),
"Tc_b": Parameter(2072.7944, "d", fixed=True),
"P_c": Parameter(42.3630, "d", fixed=True),
"K_c": Parameter(10, "m/s", fixed=False),
"e_c": Parameter(0, "", fixed=True),
"w_c": Parameter(np.pi/2, "rad", fixed=True),
"Tc_c": Parameter(2082.6252, "d", fixed=True),
"g_HIRES": Parameter(0, "m/s", fixed=False),
"gd": Parameter(0, "m/s/day", fixed=False),
"gdd": Parameter(0, "m/s/day^2", fixed=False),
"jit_HIRES": Parameter(0, "m/s", fixed=False),}
fitter.params = params
fitter.params
{'P_b': Parameter(value=20.8853, unit='d', fixed=True),
'K_b': Parameter(value=10, unit='m/s', fixed=False),
'e_b': Parameter(value=0, unit='', fixed=True),
'w_b': Parameter(value=1.5707963267948966, unit='rad', fixed=True),
'Tc_b': Parameter(value=2072.7944, unit='d', fixed=True),
'P_c': Parameter(value=42.363, unit='d', fixed=True),
'K_c': Parameter(value=10, unit='m/s', fixed=False),
'e_c': Parameter(value=0, unit='', fixed=True),
'w_c': Parameter(value=1.5707963267948966, unit='rad', fixed=True),
'Tc_c': Parameter(value=2082.6252, unit='d', fixed=True),
'g_HIRES': Parameter(value=0, unit='m/s', fixed=False),
'gd': Parameter(value=0, unit='m/s/day', fixed=False),
'gdd': Parameter(value=0, unit='m/s/day^2', fixed=False),
'jit_HIRES': Parameter(value=0, unit='m/s', fixed=False)}
Define the prior functions for the free parameters. You can see a list of available prior functions at ravest.prior.PRIOR_FUNCTIONS.
ravest.prior.PRIOR_FUNCTIONS
['Uniform',
'EccentricityUniform',
'Normal',
'TruncatedNormal',
'HalfNormal',
'Rayleigh',
'VanEylen19Mixture',
'Beta']
# Construct the priors dict. Every parameter that isn't fixed requires a prior.
priors = {
"K_b": ravest.prior.Uniform(lower=0, upper=50),
"K_c": ravest.prior.Uniform(lower=0, upper=50),
"g_HIRES": ravest.prior.Uniform(lower=-10, upper=10),
"gd": ravest.prior.Uniform(lower=-0.1, upper=0.1),
"gdd": ravest.prior.Uniform(lower=-0.01, upper=0.01),
"jit_HIRES": ravest.prior.Uniform(lower=0, upper=5),
}
fitter.priors = priors
fitter.priors
{'K_b': Uniform(lower=0, upper=50),
'K_c': Uniform(lower=0, upper=50),
'g_HIRES': Uniform(lower=-10, upper=10),
'gd': Uniform(lower=-0.1, upper=0.1),
'gdd': Uniform(lower=-0.01, upper=0.01),
'jit_HIRES': Uniform(lower=0, upper=5)}
Now that we have loaded the Fitter with the data, our parameterisation, our initial parameter values, and priors for each of the free parameters, we can now fit the free parameters of the model to the data.
First, Maximum A Posteriori (MAP) optimisation is performed to find the best-fit solution.
map_results = fitter.find_map_estimate(method="Powell")
map_results
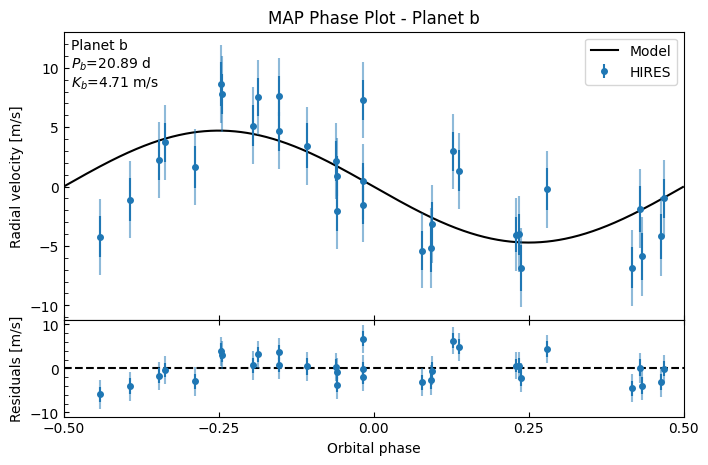
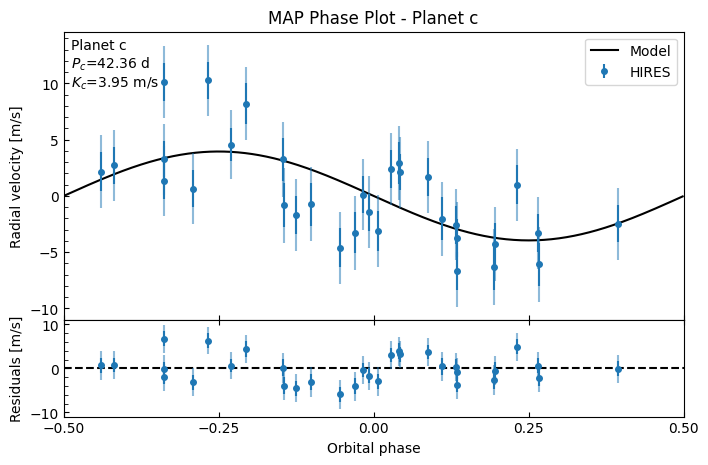
MAP parameter results: {'K_b': np.float64(4.712029698143428), 'K_c': np.float64(3.9515473266677272), 'g_HIRES': np.float64(-4.00897287645326), 'gd': np.float64(-0.03011213558494829), 'gdd': np.float64(0.0018133760186237937), 'jit_HIRES': np.float64(2.707407560244531)}
message: Optimization terminated successfully.
success: True
status: 0
fun: 89.6789245247488
x: [ 4.712e+00 3.952e+00 -4.009e+00 -3.011e-02 1.813e-03
2.707e+00]
nit: 6
direc: [[ 1.000e+00 0.000e+00 ... 0.000e+00 0.000e+00]
[ 0.000e+00 1.000e+00 ... 0.000e+00 0.000e+00]
...
[ 0.000e+00 0.000e+00 ... 1.000e+00 0.000e+00]
[ 1.765e-01 -2.888e-01 ... 6.733e-04 -1.203e-01]]
nfev: 370
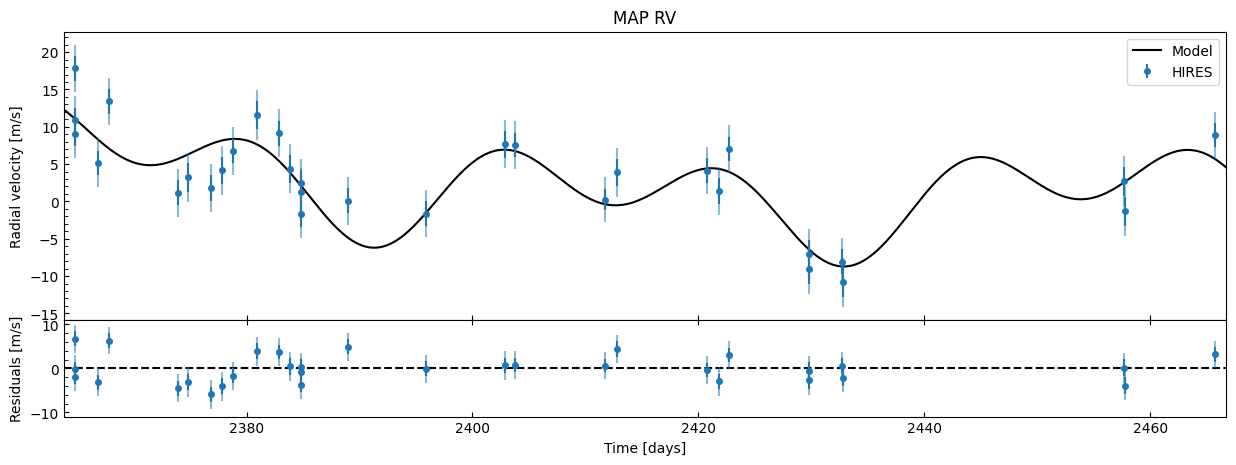
Let’s take a look at what the RV looks like with these parameter values:
fitter.plot_MAP_rv(map_result=map_results)
fitter.plot_MAP_phase(planet_letter="b", map_result=map_results)
fitter.plot_MAP_phase(planet_letter="c", map_result=map_results)
We can use MCMC to more fully explore the parameter space and estimate the parameter uncertainties. For the purposes of making this notebook run quickly, this is only running for 10000 steps - you should run considerably more. ravest enforces a minimum of at least 2 walkers per each free parameter, again though you should consider running more. You should also consider using randomly initialised starting points, rather than the MAP solution, to better explore the parameter space. Parallelisation has been (experimentally) enabled via the multiprocessing argument, this can result in significant speedups - especially for longer chains/more walkers.
nwalkers = 20
mcmc_init = fitter.generate_initial_walker_positions_from_map(map_result=map_results, nwalkers=nwalkers, verbose=False)
nsteps = 11_000 # You should definitely run for more steps than this!
# Fit the free parameters to the data. Use the MAP solution as the initial value for the MCMC walkers.
fitter.run_mcmc(initial_positions=mcmc_init, nwalkers=nwalkers, max_steps=nsteps, progress=True, multiprocessing=True) # This will take a few minutes!
INFO:root:Starting MCMC for 11000 steps...
100%|██████████| 11000/11000 [00:12<00:00, 893.74it/s]
INFO:root:...MCMC done.
Now that the MCMC is finished, the state of the emcee sampler has been saved into the Fitter object. We can therefore export the posterior samples, as a numpy array that can be passed into other functions (such as for comparing two models by calculating the Bayesian evidence - example notebook coming soon!). We can also export them into a Pandas dataframe, which keeps each parameter labelled. In both cases, we can pass in the discard_start and discard_end arguments, to drop the burn-in or “zoom” in on certain areas of the chain by discarding other parts. The thin argument keeps only every thin-th sample, and the flat argument combines all of the different walkers for each parameter into one long chain per parameter.
nburn = 1_000
thin_rate = 10
# Get the samples as a numpy array
samples = fitter.get_samples_np(discard_start=nburn, discard_end=0, thin=thin_rate, flat=False) # shape (nsteps, nwalkers, ndim)
# Get the samples as a labelled Pandas dataframe
samples_df = fitter.get_samples_df(discard_start=nburn, discard_end=0, thin=thin_rate) # shape (nsteps*nwalkers, ndim)
samples_df
| K_b | K_c | g_HIRES | gd | gdd | jit_HIRES | |
|---|---|---|---|---|---|---|
| 0 | 4.555234 | 3.570486 | -5.480046 | -0.033807 | 0.002707 | 3.011506 |
| 1 | 5.821208 | 5.242123 | -2.403020 | -0.067440 | 0.000344 | 2.815983 |
| 2 | 3.130616 | 3.729957 | -4.490438 | -0.045043 | 0.001990 | 2.512436 |
| 3 | 3.260756 | 2.343956 | -4.726766 | -0.036580 | 0.003031 | 2.134233 |
| 4 | 4.501934 | 3.618039 | -3.893632 | -0.070639 | 0.001277 | 3.371615 |
| ... | ... | ... | ... | ... | ... | ... |
| 19995 | 6.066869 | 4.044074 | -5.508944 | -0.091130 | 0.001211 | 4.171493 |
| 19996 | 3.792657 | 4.256248 | -2.255034 | -0.068861 | 0.000550 | 4.032558 |
| 19997 | 4.441741 | 4.241982 | -4.340454 | -0.023338 | 0.002421 | 2.606453 |
| 19998 | 4.373168 | 5.139915 | -2.911295 | -0.037556 | 0.000804 | 2.492818 |
| 19999 | 5.396622 | 5.157662 | -3.109277 | -0.024683 | 0.001176 | 3.226145 |
20000 rows × 6 columns
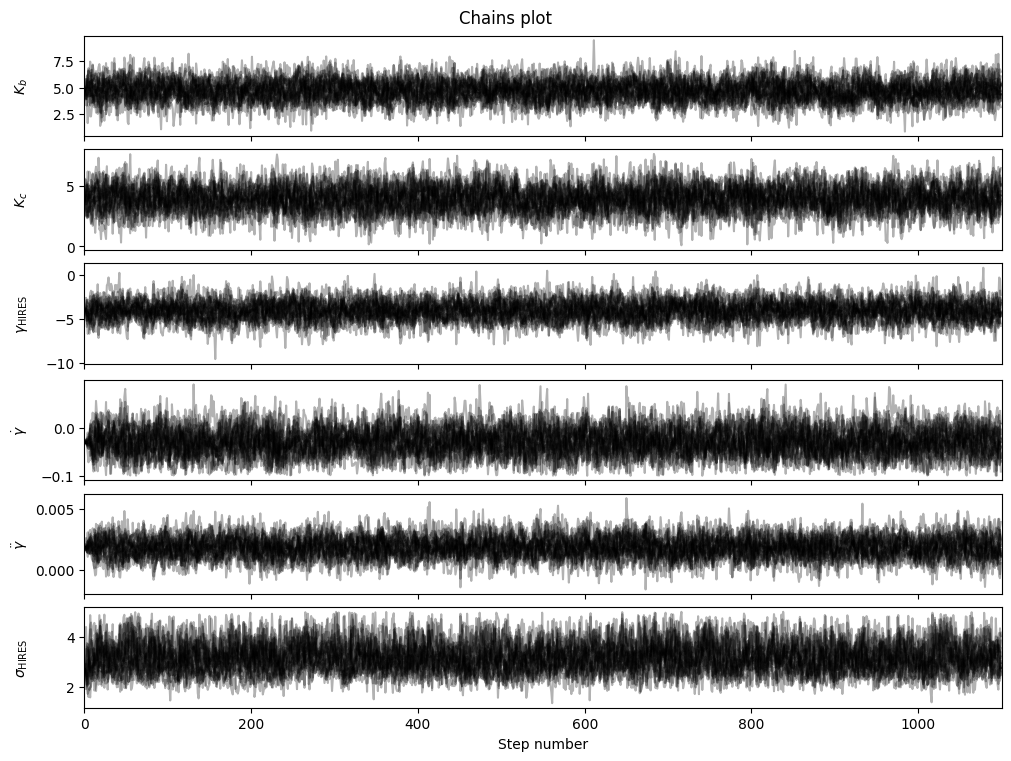
To inspect the chains visually, we can plot (and optionally save) the time series of each parameter in the chain. We see that after a brief period aorund the initial values (which we expect, as we started the walkers at the MAP values, so they’ll be starting at an area of maximised likelihood), they eventually break out and start exploring the parameter space more. For all future plots we can discard this initial “burn-in” with the discard_start argument.
fitter.plot_chains(discard_start=0, discard_end=0, thin=thin_rate, save=False)
We can visualise the posterior parameter distributions in corner plots, using the corner module.
fitter.plot_corner(discard_start=nburn, discard_end=0, thin=thin_rate, plot_datapoints=True, save=False)
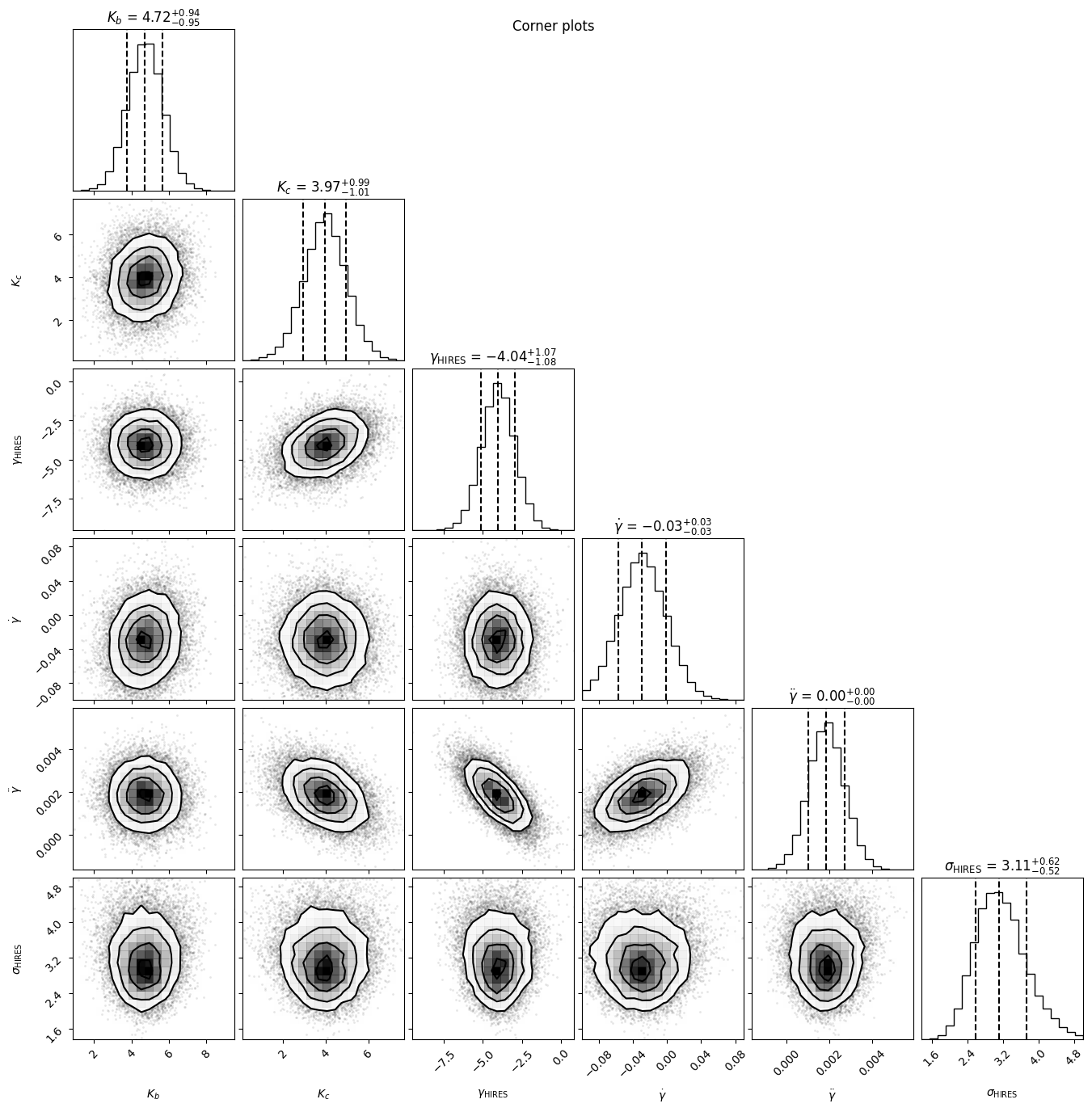
Inspecting the posteriors, we can see the 16th, 50th and 84th percentiles are shown, which could be used for a quoted value and uncertainty. It’s a good idea to inspect the posterior distribution visually with the corner plots though, as they may not always be nice Gaussians, which means those percentiles may not be a good representation. (This is often the case for eccentricity!). For further analysis and inspection, recall that we can get a dataframe of the samples (e.g. to plot them in a histogram to inspect the distribution closer) by using the Fitter.get_samples_df() method that we saw earlier.
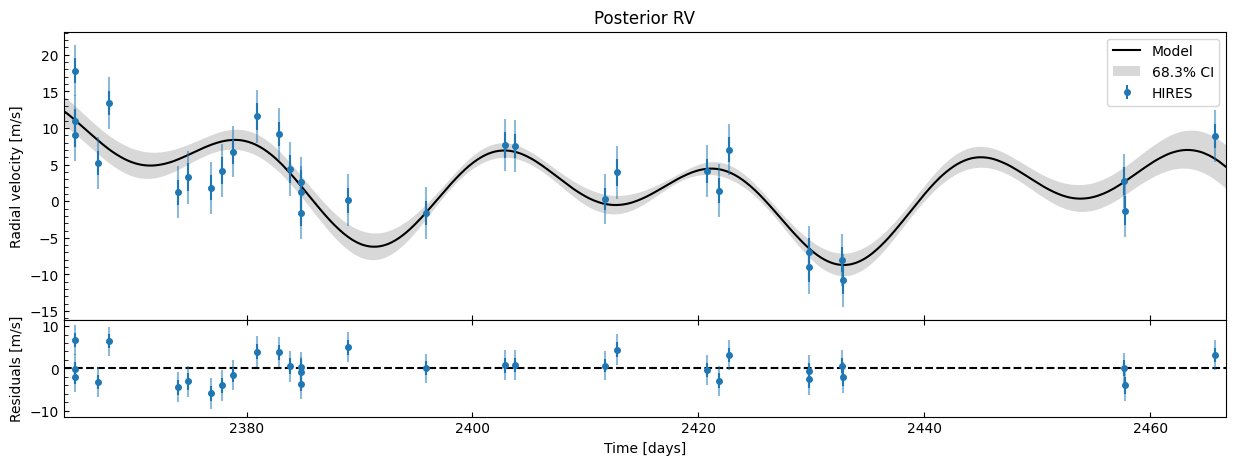
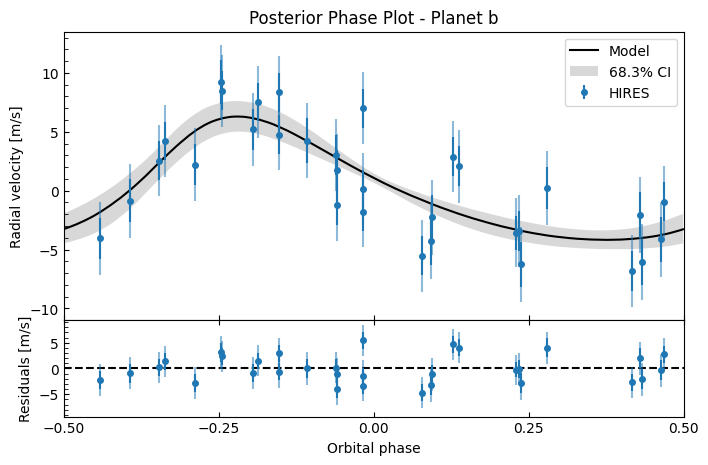
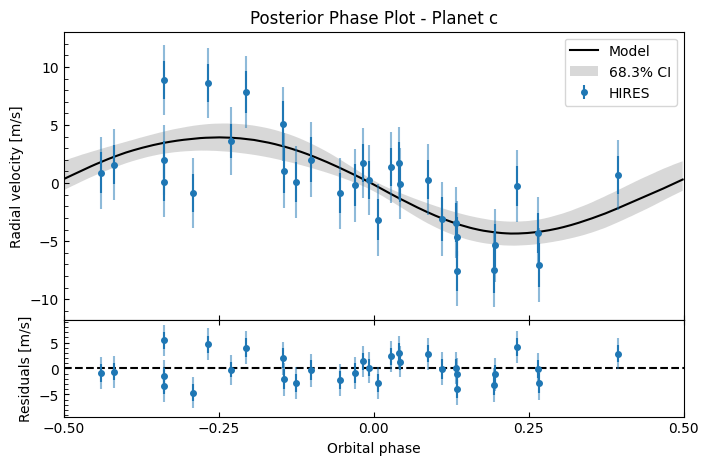
Let’s see what the posterior RV looks like - we’ll calcuate the RV for each of the MCMC samples, then we plot the median RV and 16-84 percentiles at each timestep. We’ll also look at each planet’s contribution in isolation with phase plots.
fitter.plot_posterior_rv(discard_start=nburn, discard_end=0, thin=thin_rate)
fitter.plot_posterior_phase("b", discard_start=nburn, discard_end=0, thin=thin_rate)
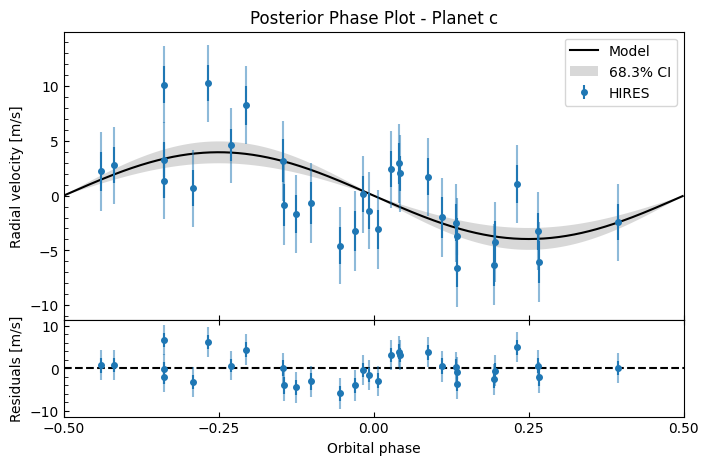
fitter.plot_posterior_phase("c", discard_start=nburn, discard_end=0, thin=thin_rate)
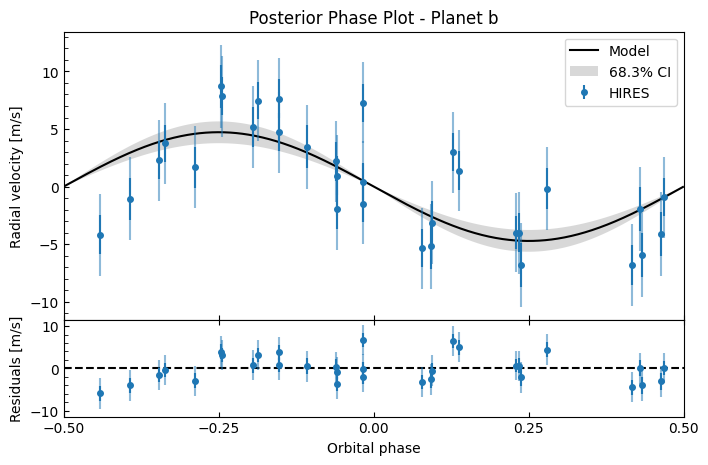
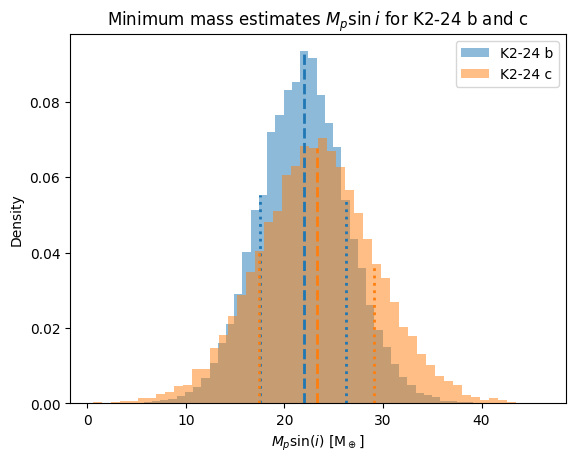
To calculate planetary mass estimates \(M_p\sin{i}\), we need to know the stellar mass. Using the value \(M_\star=1.12\pm0.05\) used in Petigura et al. 2016, we can generate a distribution of stellar mass values from the published value and uncertainty, and draw from that distribution to use as the value of \(M_\star\) in the conversion equation.
# Stellar mass values from Petigura et al. 2016
mstar_val = 1.12 # [M_sun]
mstar_err = 0.05 # [M_sun]
# Create a distribution of stellar mass values from the published value and uncertainty
np.random.seed(47) # For reproducibility
mstar = np.random.normal(loc=mstar_val, scale=mstar_err, size=len(samples_df))
# Ensure all values in mstar are positive (incredibly unlikely to be an issue with these values, but just in case)
while any(mstar <= 0):
mstar[mstar <= 0] = np.random.normal(loc=mstar_val, scale=mstar_err, size=sum(mstar <= 0))
# get the posterior samples (both free and fixed) as a dictionary
posterior_params = fitter.get_mcmc_posterior_dict(discard_start=nburn, discard_end=0, thin=thin_rate)
# use the MCMC samples and the stellar mass distribution to get a distribution for Mp sin(i)
mpsini_b = calculate_mpsini(mstar, posterior_params["P_b"], posterior_params["K_b"], posterior_params["e_b"], unit="M_earth")
mpsini_c = calculate_mpsini(mstar, posterior_params["P_c"], posterior_params["K_c"], posterior_params["e_c"], unit="M_earth")
# Plot the mpsini posterior distributions overlapping
fig, ax = plt.subplots(1, 1)
ax.set_title("Minimum mass estimates $M_p\\sin{i}$ for K2-24 b and c")
ax.set_xlabel("$M_p \\sin(i)$ [M$_\\oplus$]")
ax.set_ylabel("Density")
# Plot both histograms first, normalised so they're visually comparable
plot_b = ax.hist(mpsini_b, bins=50, color="tab:blue", alpha=0.5, label="K2-24 b", density=True)
plot_c = ax.hist(mpsini_c, bins=50, color="tab:orange", alpha=0.5, label="K2-24 c", density=True)
# Get the final y-axis bound after both histograms are drawn
_, ymax = ax.get_ybound()
# Overplot percentile lines for planet b
ps_b = np.percentile(mpsini_b, [16, 50, 84])
heights_b = plot_b[0][np.searchsorted(plot_b[1], ps_b, side='left') - 1]
ax.axvline(ps_b[0], color='tab:blue', linestyle=':', linewidth=2, ymax=heights_b[0] / ymax)
ax.axvline(ps_b[1], color='tab:blue', linestyle='--', linewidth=2, ymax=heights_b[1] / ymax)
ax.axvline(ps_b[2], color='tab:blue', linestyle=':', linewidth=2, ymax=heights_b[2] / ymax)
# Overplot percentile lines for planet c
ps_c = np.percentile(mpsini_c, [16, 50, 84])
heights_c = plot_c[0][np.searchsorted(plot_c[1], ps_c, side='left') - 1]
ax.axvline(ps_c[0], color='tab:orange', linestyle=':', linewidth=2, ymax=heights_c[0] / ymax)
ax.axvline(ps_c[1], color='tab:orange', linestyle='--', linewidth=2, ymax=heights_c[1] / ymax)
ax.axvline(ps_c[2], color='tab:orange', linestyle=':', linewidth=2, ymax=heights_c[2] / ymax)
ax.legend(loc="upper right")
print(f"K2-24 b Mpsini: {ps_b[1]:.2f} +{ps_b[2]-ps_b[1]:.2f} -{ps_b[1]-ps_b[0]:.2f} M_earth")
print(f"K2-24 c Mpsini: {ps_c[1]:.2f} +{ps_c[2]-ps_c[1]:.2f} -{ps_c[1]-ps_c[0]:.2f} M_earth")
K2-24 b Mpsini: 21.93 +4.34 -4.45 M_earth
K2-24 c Mpsini: 23.26 +5.85 -5.86 M_earth
Eccentric orbits
Let’s make a new Fitter object and fit for eccentricity. We’ll fit in the \(\sqrt{e}\cos{\omega_\star}\) and \(\sqrt{e}\sin{\omega_\star}\) parameterisation.
# Fit in the sqrt(e) parameterisation
parameterisation_se = Parameterisation("P K secosw sesinw Tc")
fitter_se = Fitter(planet_letters=["b","c"], parameterisation=parameterisation_se)
fitter_se.add_data(time=data["time"].to_numpy(),
vel=data["vel"].to_numpy(),
velerr=data["errvel"].to_numpy(),
instrument=data["tel"].to_numpy(),
t0=2420)
print(fitter_se.t0)
# Construct the params dict
# These values will be used as your initial guess for the fit
params_se = {"P_b": Parameter(20.8853, "d", fixed=True),
"K_b": Parameter(np.exp(1.55037), "m/s", fixed=False),
"secosw_b": Parameter(0.01, "", fixed=False),
"sesinw_b": Parameter(0.01, "", fixed=False),
"Tc_b": Parameter(2072.7944, "d", fixed=True),
"P_c": Parameter(42.3630, "d", fixed=True),
"K_c": Parameter(np.exp(1.37648), "m/s", fixed=False),
"secosw_c": Parameter(0.01, "", fixed=False),
"sesinw_c": Parameter(0.01, "", fixed=False),
"Tc_c": Parameter(2082.6252, "d", fixed=True),
"g_HIRES": Parameter(-3.99195, "m/s", fixed=False),
"gd": Parameter(0, "m/s/day", fixed=False),
"gdd": Parameter(0, "m/s/day^2", fixed=False),
"jit_HIRES": Parameter(2.09753, "m/s", fixed=False),
}
fitter_se.params = params_se
fitter_se.params
2420
{'P_b': Parameter(value=20.8853, unit='d', fixed=True),
'K_b': Parameter(value=np.float64(4.7132137490982124), unit='m/s', fixed=False),
'secosw_b': Parameter(value=0.01, unit='', fixed=False),
'sesinw_b': Parameter(value=0.01, unit='', fixed=False),
'Tc_b': Parameter(value=2072.7944, unit='d', fixed=True),
'P_c': Parameter(value=42.363, unit='d', fixed=True),
'K_c': Parameter(value=np.float64(3.9609345702082397), unit='m/s', fixed=False),
'secosw_c': Parameter(value=0.01, unit='', fixed=False),
'sesinw_c': Parameter(value=0.01, unit='', fixed=False),
'Tc_c': Parameter(value=2082.6252, unit='d', fixed=True),
'g_HIRES': Parameter(value=-3.99195, unit='m/s', fixed=False),
'gd': Parameter(value=0, unit='m/s/day', fixed=False),
'gdd': Parameter(value=0, unit='m/s/day^2', fixed=False),
'jit_HIRES': Parameter(value=2.09753, unit='m/s', fixed=False)}
We could put Uniform priors on the \(\sqrt{e}\cos{\omega_\star}\) and \(\sqrt{e}\sin{\omega_\star}\) parameters directly, but here we’ll show how you can also put priors on their equivalent parameters (\(e\) and \(\omega_\star\)) from the default parameterisation (\(P, K, e, \omega_\star, T_c\)) too. Note the use of EccentricityUniform which allows \(e=0\) exactly, whereas a standard Uniform prior is closed-interval and won’t allow \(e=0\) exactly.
# Construct the priors dict. Every parameter that isn't fixed requires a prior.
priors_se = {
"K_b": ravest.prior.Uniform(lower=0, upper=50),
"e_b": ravest.prior.EccentricityUniform(upper=0.8), # Prior on e & w, even though fitting in secosw sesinw
"w_b": ravest.prior.Uniform(lower=-np.pi, upper=np.pi),
"K_c": ravest.prior.Uniform(lower=0, upper=50),
"e_c": ravest.prior.EccentricityUniform(upper=0.8), # Prior on e & w, even though fitting in secosw sesinw
"w_c": ravest.prior.Uniform(lower=-np.pi, upper=np.pi),
"g_HIRES": ravest.prior.Uniform(lower=-10, upper=10),
"gd": ravest.prior.Uniform(lower=-0.1, upper=0.1),
"gdd": ravest.prior.Uniform(lower=-0.01, upper=0.01),
"jit_HIRES": ravest.prior.Uniform(lower=0, upper=5),
}
fitter_se.priors = priors_se
fitter_se.priors
{'K_b': Uniform(lower=0, upper=50),
'e_b': EccentricityUniform(upper=0.8),
'w_b': Uniform(lower=-3.141592653589793, upper=3.141592653589793),
'K_c': Uniform(lower=0, upper=50),
'e_c': EccentricityUniform(upper=0.8),
'w_c': Uniform(lower=-3.141592653589793, upper=3.141592653589793),
'g_HIRES': Uniform(lower=-10, upper=10),
'gd': Uniform(lower=-0.1, upper=0.1),
'gdd': Uniform(lower=-0.01, upper=0.01),
'jit_HIRES': Uniform(lower=0, upper=5)}
map_results_se = fitter_se.find_map_estimate(method="Powell")
map_results_se
MAP parameter results: {'K_b': np.float64(6.091217047674938), 'secosw_b': np.float64(0.3895342708288487), 'sesinw_b': np.float64(-0.4217350139051482), 'K_c': np.float64(4.360165979963281), 'secosw_c': np.float64(-0.13122587509086747), 'sesinw_c': np.float64(0.3635160601988869), 'g_HIRES': np.float64(-4.567179914895435), 'gd': np.float64(-0.030223243014710598), 'gdd': np.float64(0.002085547196419739), 'jit_HIRES': np.float64(1.9482056970531976)}
message: Optimization terminated successfully.
success: True
status: 0
fun: 86.0376836870328
x: [ 6.091e+00 3.895e-01 -4.217e-01 4.360e+00 -1.312e-01
3.635e-01 -4.567e+00 -3.022e-02 2.086e-03 1.948e+00]
nit: 10
direc: [[ 1.000e+00 0.000e+00 ... 0.000e+00 0.000e+00]
[ 0.000e+00 1.000e+00 ... 0.000e+00 0.000e+00]
...
[ 0.000e+00 0.000e+00 ... 0.000e+00 1.000e+00]
[-8.368e-02 -1.924e-03 ... 1.142e-04 8.957e-03]]
nfev: 1115
fitter_se.plot_MAP_rv(map_result=map_results_se)
fitter_se.plot_MAP_phase(planet_letter="b", map_result=map_results_se)
fitter_se.plot_MAP_phase(planet_letter="c", map_result=map_results_se)
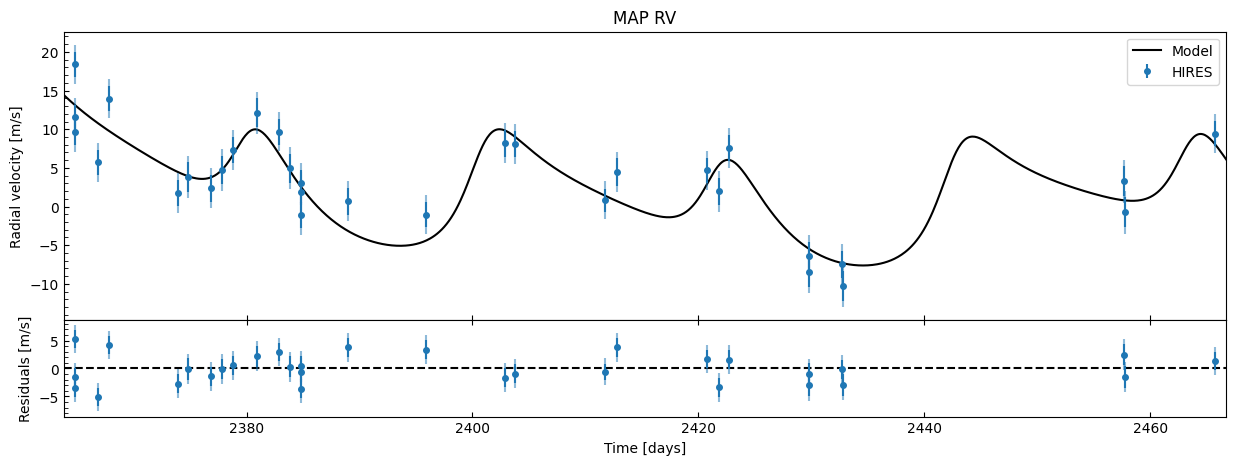
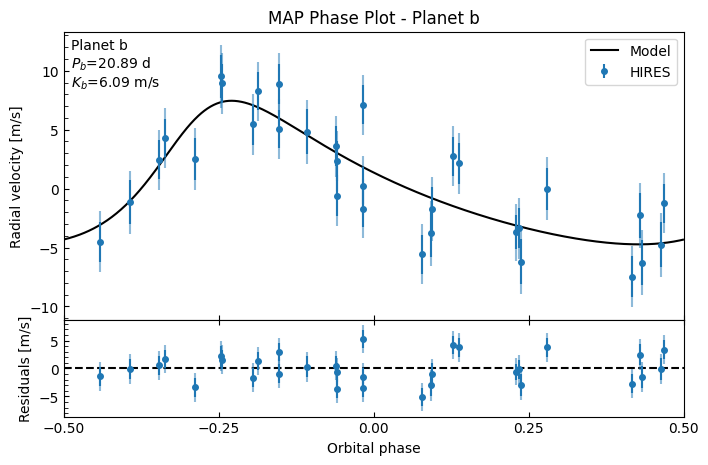
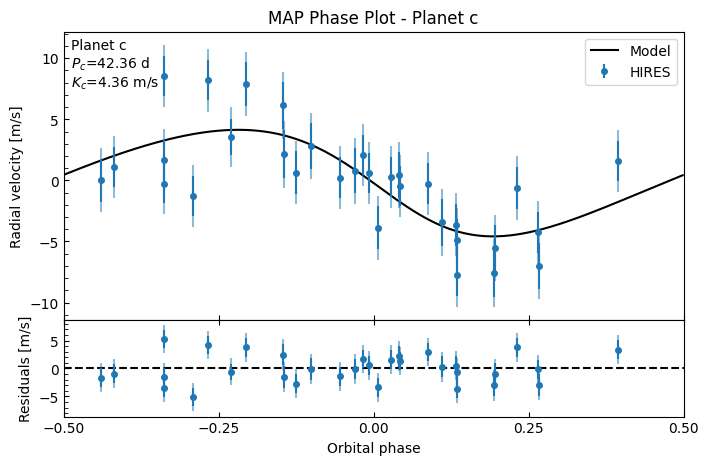
We can already see that the residuals are generally tighter than they were in the circular case.
nwalkers_se = 20
mcmc_init_se = fitter_se.generate_initial_walker_positions_from_map(map_result=map_results_se, nwalkers=nwalkers_se, verbose=False)
nsteps = 11_000
# Fit the free parameters to the data
samples_se = fitter_se.run_mcmc(initial_positions=mcmc_init_se, nwalkers=nwalkers_se, max_steps=nsteps, progress=True, multiprocessing=True) # This will take a while!
INFO:root:Starting MCMC for 11000 steps...
100%|██████████| 11000/11000 [00:13<00:00, 811.06it/s]
INFO:root:...MCMC done.
# Get the samples as a numpy array
samples_se = fitter_se.get_samples_np(discard_start=nburn, discard_end=0, thin=thin_rate, flat=False) # shape (nsteps, nwalkers, ndim)
# Get the samples as a labelled Pandas dataframe
samples_df_se = fitter_se.get_samples_df(discard_start=nburn, discard_end=0, thin=thin_rate) # shape (nsteps*nwalkers, ndim)
samples_df_se
| K_b | secosw_b | sesinw_b | K_c | secosw_c | sesinw_c | g_HIRES | gd | gdd | jit_HIRES | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.276151 | 0.426291 | -0.438663 | 4.234029 | -0.299408 | -0.115579 | -4.740009 | -0.046416 | 0.002147 | 3.047270 |
| 1 | 6.548703 | 0.485535 | 0.077619 | 5.978530 | 0.389175 | -0.296649 | -3.891968 | -0.038365 | 0.000129 | 3.643884 |
| 2 | 5.812652 | 0.248510 | -0.403389 | 3.457636 | 0.112676 | -0.034671 | -5.654597 | -0.034267 | 0.002476 | 2.245252 |
| 3 | 5.049782 | 0.366184 | -0.388658 | 3.060960 | -0.269598 | -0.236240 | -6.359627 | -0.038956 | 0.003585 | 2.958553 |
| 4 | 7.456244 | 0.488994 | -0.287324 | 4.937372 | 0.087867 | 0.542340 | -4.512295 | -0.037840 | 0.001433 | 1.914770 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19995 | 4.597718 | 0.355896 | -0.306284 | 5.652989 | -0.218041 | -0.236409 | -2.836064 | -0.090990 | -0.000027 | 3.190810 |
| 19996 | 5.929075 | 0.404337 | -0.230847 | 4.670643 | 0.029798 | -0.026923 | -3.970535 | 0.022459 | 0.002236 | 2.124973 |
| 19997 | 5.557085 | 0.324100 | -0.560176 | 5.016413 | -0.227160 | -0.350574 | -5.025933 | -0.036990 | 0.002523 | 2.043473 |
| 19998 | 5.910218 | 0.476178 | -0.280470 | 3.476289 | 0.036034 | 0.174033 | -4.051131 | -0.075451 | 0.001834 | 3.957118 |
| 19999 | 8.224147 | 0.393809 | -0.358631 | 4.329537 | 0.165256 | 0.359303 | -6.027280 | -0.029372 | 0.002309 | 2.575552 |
20000 rows × 10 columns
fitter_se.plot_chains(discard_start=0, discard_end=0, thin=thin_rate, save=False)
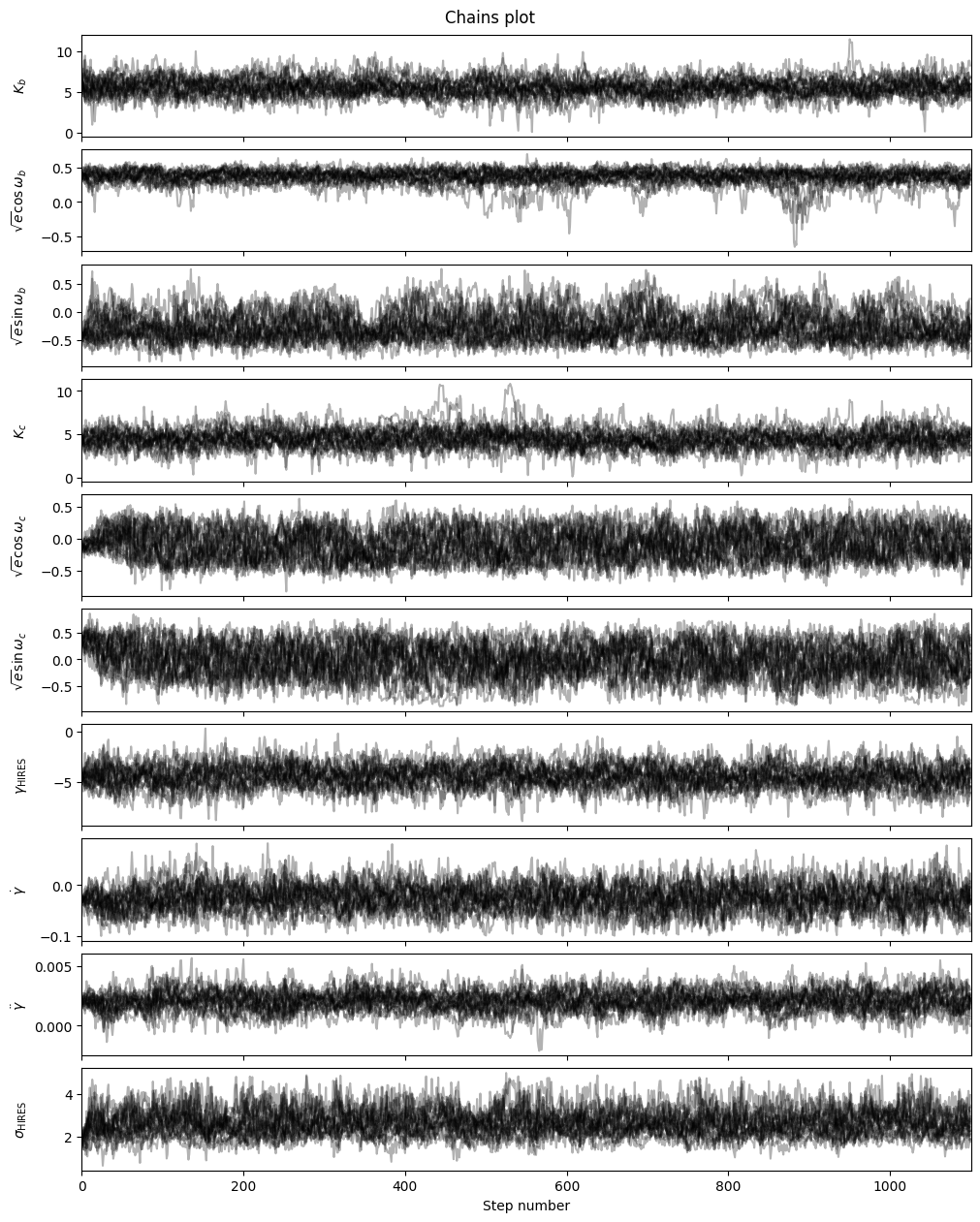
fitter_se.plot_corner(discard_start=nburn, discard_end=0, thin=thin_rate, plot_datapoints=True, save=False)

We can convert \(\sqrt{e}\cos{\omega_\star}\) and \(\sqrt{e}\sin{\omega_\star}\) chains back to \(e\) (and \(\omega_\star\)) to inspect the posterior eccentricity directly.
eb_array, wb_array = parameterisation_se.convert_secosw_sesinw_to_e_w(samples_df_se["secosw_b"], samples_df_se["sesinw_b"])
ec_array, wc_array = parameterisation_se.convert_secosw_sesinw_to_e_w(samples_df_se["secosw_c"], samples_df_se["sesinw_c"])
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,4))
ax1.hist(eb_array, bins=100, histtype="step", label="Planet b")
ax1.hist(ec_array, bins=100, histtype="step", label="Planet c")
ax1.set_xlabel("Eccentricity")
ax1.set_ylabel("Number of samples")
ax1.legend()
ax2.hist(wb_array, bins=100, histtype="step", label="Planet b")
ax2.hist(wc_array, bins=100, histtype="step", label="Planet c")
ax2.set_xlabel("Argument of periastron [rad]")
ax2.set_ylabel("Number of samples")
ax2.legend()
plt.show()
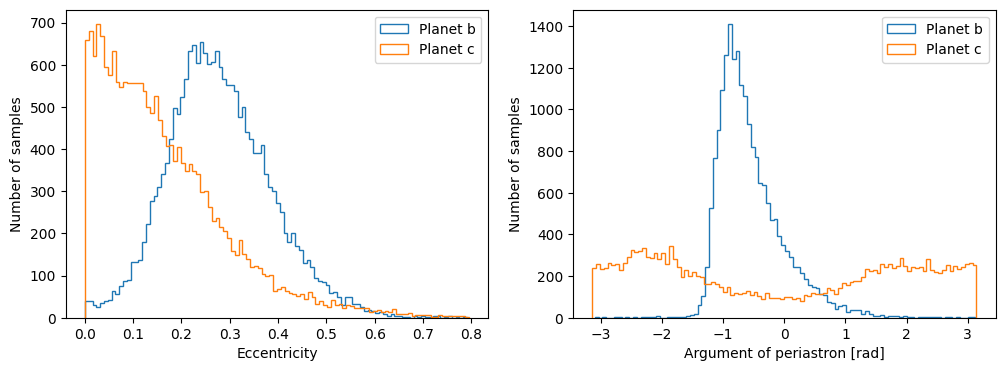
Planet b definitely looks eccentric, harder to tell for planet c though. (Remember \(\omega_\star\) becomes undefined when \(e=0\), which might explain why \(\omega_{\star,c}\) has such a wide spread: because a lot of the samples are where \(e_c\) is close to 0, walkers making large moves in \(\omega_{\star,c}\) will have little effect on the resultant RV. So with an uninformative prior, the walker will just sweep through the entire parameter space for \(\omega_{\star,c}\) without much effect on the log-likelihood).
Let’s inspect how well our models matches the observed RV data. These functions evaluate the RV for every sample in the chains (after discarding and thinning), and plots the median and 68.3% interval of the RV at every timestep. (N.B. thinning can be useful here - these plots can take a while to generate as it has to calculate the RV curve for every sample in the chain.)
fitter_se.plot_posterior_rv(discard_start=nburn, discard_end=0, thin=thin_rate)
fitter_se.plot_posterior_phase("b", discard_start=nburn, discard_end=0, thin=thin_rate)
fitter_se.plot_posterior_phase("c", discard_start=nburn, discard_end=0, thin=thin_rate)
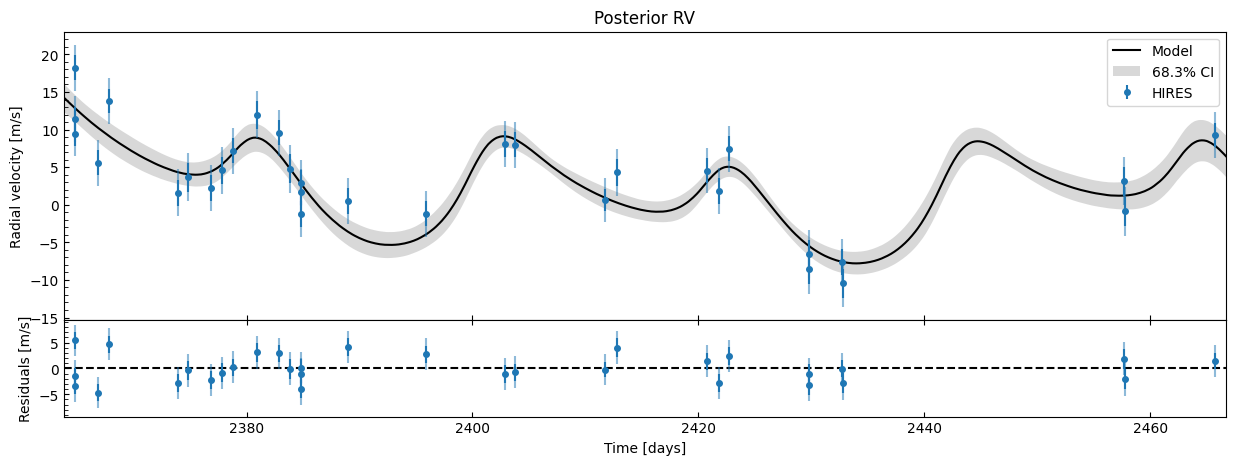
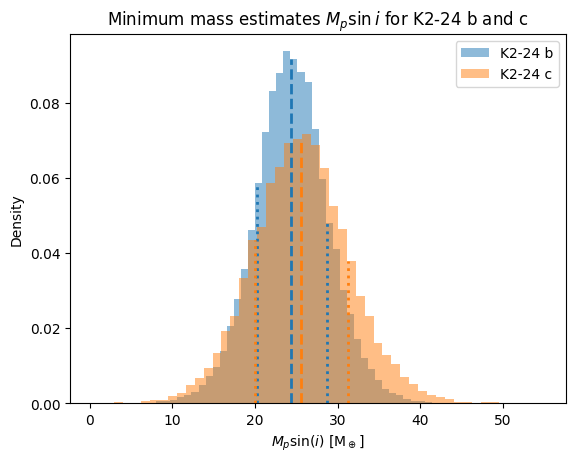
Let’s see how allowing for eccentric orbits affects the mass estimates \(M_p\sin{i}\). We will use the same stellar mass values from Petigura et al. 2016 that we used earlier.
# Create a distribution of stellar mass values using the same published value and uncertainty as before
np.random.seed(47) # For reproducibility
mstar = np.random.normal(loc=mstar_val, scale=mstar_err, size=len(samples_df_se))
# Ensure all values in mstar are positive (incredibly unlikely to be an issue with these values, but just in case)
while any(mstar <= 0):
print(mstar[mstar <= 0])
mstar[mstar <= 0] = np.random.normal(loc=mstar_val, scale=mstar_err, size=sum(mstar <= 0))
# get the posterior samples (both free and fixed) as a dictionary
posterior_params_se = fitter_se.get_mcmc_posterior_dict(discard_start=nburn, discard_end=0, thin=thin_rate) # get the fixed value for fixed parameters, get the MCMC samples for the free parameters
# we need to convert secosw and sesinw to e and w
# let's do this using the parameterisation class, parameterisation_se
posterior_params_se["e_b"], posterior_params_se["w_b"] = parameterisation_se.convert_secosw_sesinw_to_e_w(posterior_params_se["secosw_b"], posterior_params_se["sesinw_b"])
# and the same for _c
posterior_params_se["e_c"], posterior_params_se["w_c"] = parameterisation_se.convert_secosw_sesinw_to_e_w(posterior_params_se["secosw_c"], posterior_params_se["sesinw_c"])
# use the MCMC samples and the stellar mass distribution to get a distribution for Mp sin(i)
mpsini_b_se = calculate_mpsini(mstar, posterior_params_se["P_b"], posterior_params_se["K_b"], posterior_params_se["e_b"], unit="M_earth")
mpsini_c_se = calculate_mpsini(mstar, posterior_params_se["P_c"], posterior_params_se["K_c"], posterior_params_se["e_c"], unit="M_earth")
# Plot the mpsini posterior distributions overlapping
fig, ax = plt.subplots(1, 1)
ax.set_title("Minimum mass estimates $M_p\\sin{i}$ for K2-24 b and c")
ax.set_xlabel("$M_p \\sin(i)$ [M$_\\oplus$]")
ax.set_ylabel("Density")
# Plot both histograms first, normalised so they're visually comparable
plot_b_se = ax.hist(mpsini_b_se, bins=50, color="tab:blue", alpha=0.5, label="K2-24 b", density=True)
plot_c_se = ax.hist(mpsini_c_se, bins=50, color="tab:orange", alpha=0.5, label="K2-24 c", density=True)
# Get the final y-axis bound after both histograms are drawn
_, ymax_se = ax.get_ybound()
# Overplot percentile lines for planet b
ps_b_se = np.percentile(mpsini_b_se, [16, 50, 84])
heights_b = plot_b_se[0][np.searchsorted(plot_b_se[1], ps_b_se, side='left') - 1]
ax.axvline(ps_b_se[0], color='tab:blue', linestyle=':', linewidth=2, ymax=heights_b[0] / ymax_se)
ax.axvline(ps_b_se[1], color='tab:blue', linestyle='--', linewidth=2, ymax=heights_b[1] / ymax_se)
ax.axvline(ps_b_se[2], color='tab:blue', linestyle=':', linewidth=2, ymax=heights_b[2] / ymax_se)
# Overplot percentile lines for planet c
ps_c_se = np.percentile(mpsini_c_se, [16, 50, 84])
heights_c = plot_c_se[0][np.searchsorted(plot_c_se[1], ps_c_se, side='left') - 1]
ax.axvline(ps_c_se[0], color='tab:orange', linestyle=':', linewidth=2, ymax=heights_c[0] / ymax_se)
ax.axvline(ps_c_se[1], color='tab:orange', linestyle='--', linewidth=2, ymax=heights_c[1] / ymax_se)
ax.axvline(ps_c_se[2], color='tab:orange', linestyle=':', linewidth=2, ymax=heights_c[2] / ymax_se)
ax.legend(loc="upper right")
print(f"K2-24 b Mpsini: {ps_b_se[1]:.2f} +{ps_b_se[2]-ps_b_se[1]:.2f} -{ps_b_se[1]-ps_b_se[0]:.2f} M_earth")
print(f"K2-24 c Mpsini: {ps_c_se[1]:.2f} +{ps_c_se[2]-ps_c_se[1]:.2f} -{ps_c_se[1]-ps_c_se[0]:.2f} M_earth")
K2-24 b Mpsini: 24.42 +4.35 -4.21 M_earth
K2-24 c Mpsini: 25.58 +5.63 -5.63 M_earth
Model Comparison
Let’s compare the mass estimates for the two planets in both the circular and eccentric models.
print(f"K2-24 b Mpsini (circular) : {ps_b[1]:.2f} +{ps_b[2]-ps_b[1]:.2f} -{ps_b[1]-ps_b[0]:.2f} M_earth")
print(f"K2-24 b Mpsini (eccentric): {ps_b_se[1]:.2f} +{ps_b_se[2]-ps_b_se[1]:.2f} -{ps_b_se[1]-ps_b_se[0]:.2f} M_earth")
print(f"K2-24 c Mpsini (circular) : {ps_c[1]:.2f} +{ps_c[2]-ps_c[1]:.2f} -{ps_c[1]-ps_c[0]:.2f} M_earth")
print(f"K2-24 c Mpsini (eccentric): {ps_c_se[1]:.2f} +{ps_c_se[2]-ps_c_se[1]:.2f} -{ps_c_se[1]-ps_c_se[0]:.2f} M_earth")
K2-24 b Mpsini (circular) : 21.93 +4.34 -4.45 M_earth
K2-24 b Mpsini (eccentric): 24.42 +4.35 -4.21 M_earth
K2-24 c Mpsini (circular) : 23.26 +5.85 -5.86 M_earth
K2-24 c Mpsini (eccentric): 25.58 +5.63 -5.63 M_earth
Now let’s compare the circular and eccentric models quantitatively using statistical metrics.
# Calculate metrics for circular model
fitter_samples = fitter.get_samples_np(discard_start=nburn, discard_end=0, thin=thin_rate, flat=True)
fitter_medians = np.percentile(fitter_samples, 50, axis=0)
fitter_complete_dict = fitter.build_params_dict(fitter_medians)
fitter_chi2 = fitter.calculate_chi2(fitter_complete_dict)
fitter_loglike = fitter.calculate_log_likelihood(fitter_complete_dict)
fitter_aic = fitter.calculate_aic(fitter_complete_dict)
fitter_bic = fitter.calculate_bic(fitter_complete_dict)
print("Circular model metrics at 50th percentile:")
print(f" Chi2: {fitter_chi2:.2f}")
print(f" Log-likelihood: {fitter_loglike:.2f}")
print(f" AIC: {fitter_aic:.2f}")
print(f" BIC: {fitter_bic:.2f}")
Circular model metrics at 50th percentile:
Chi2: 26.00
Log-likelihood: -83.09
AIC: 178.17
BIC: 186.97
# Calculate metrics for eccentric model
fitter_se_samples = fitter_se.get_samples_np(discard_start=nburn, discard_end=0, thin=thin_rate, flat=True)
fitter_se_medians = np.percentile(fitter_se_samples, 50, axis=0)
fitter_se_complete_dict = fitter_se.build_params_dict(fitter_se_medians)
fitter_se_chi2 = fitter_se.calculate_chi2(fitter_se_complete_dict)
fitter_se_loglike = fitter_se.calculate_log_likelihood(fitter_se_complete_dict)
fitter_se_aic = fitter_se.calculate_aic(fitter_se_complete_dict)
fitter_se_bic = fitter_se.calculate_bic(fitter_se_complete_dict)
print("Eccentric model metrics at 50th percentile:")
print(f" Chi2: {fitter_se_chi2:.2f}")
print(f" Log-likelihood: {fitter_se_loglike:.2f}")
print(f" AIC: {fitter_se_aic:.2f}")
print(f" BIC: {fitter_se_bic:.2f}")
Eccentric model metrics at 50th percentile:
Chi2: 23.68
Log-likelihood: -77.34
AIC: 174.68
BIC: 189.34
print(f"\n{'Metric':<20} {'Circular':>12} {'Eccentric':>12} {'':>20}")
print("-" * 70)
print(f"{'Free parameters':<20} {fitter.ndim:>12} {fitter_se.ndim:>12}")
print(f"{'Chi2':<20} {fitter_chi2:>12.2f} {fitter_se_chi2:>12.2f} {'(lower is better)':>20}")
print(f"{'Log-likelihood':<20} {fitter_loglike:>12.2f} {fitter_se_loglike:>12.2f} {'(higher is better)':>20}")
print(f"{'AIC':<20} {fitter_aic:>12.2f} {fitter_se_aic:>12.2f} {'(lower is better)':>20}")
print(f"{'BIC':<20} {fitter_bic:>12.2f} {fitter_se_bic:>12.2f} {'(lower is better)':>20}")
Metric Circular Eccentric
----------------------------------------------------------------------
Free parameters 6 10
Chi2 26.00 23.68 (lower is better)
Log-likelihood -83.09 -77.34 (higher is better)
AIC 178.17 174.68 (lower is better)
BIC 186.97 189.34 (lower is better)
The eccentric model is preferred across three of the metrics. The lower \(\chi^2\) and higher \(\ln{\mathcal{L}}\) simply show a better numerical fit to the data. Remember that the AIC and BIC both are penalised as the number of free parameters increases (to prevent overfitting), therefore it is interesting that with BIC the circular model is very slightly preferred. Looking at the earlier results, there isn’t much evidence that planet c is eccentric, so the contribution to the RV (and therefore likelihood) for that planet will be nearly the same as in the circular model, but now the AIC and BIC are penalised by the 4 additional free eccentricity parameters (and the penalty term in BIC is stronger than AIC.)
Perhaps an exercise for the reader is seeing what happens if you fix planet c to be circular, but allow planet b to be eccentric…